- Fireworks 스킨 16
아침놀 Blog
Daybreakin Things
246 Entries : Results for 컴퓨터
- Posted
- Filed under 컴퓨터
요즘 이거 하면서 다른 일을 아무것도 못하고 있다. 한자 필기 인식을 위한 graph similarity 측정 알고리즘을 만드는 건데, 사실 이거 제대로 하려면 석박사급 논문이 될 것이고-_- 인터넷이나 논문 자료를 보고 해도 되는 대신 구현은 직접 하라는 조건이다. (숙제내용 참고)
중요한 건, 이 프로젝트 덕분에 python에 대해서 다시금 놀라고 있다는 것이다. 원래는 이걸 Java로 짜야 하나, 일단 알고리즘 성능이나 정확도를 보기 위해서 prototype을 Python으로 작성하고 있다. 내가 java에 비해 Python을 훨씬 조금밖에 다루지 않았는데도 만드는 속도나 편리함은 정말 대단하다.
하여간 이놈의 프로젝트를 마무리해야 본격적인 시험 공부에 돌입할 수 있을 것 갈다. -_- (잘못하면 밤새야 할지도..?)
- Response
- You can track responses via RSS / ATOM feed

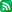
- Posted
- Filed under 컴퓨터
태터툴즈 1.0의 오픈베타 버전을 제 개인 서버에 설치했습니다. 이미 예전부터 utf-8 환경을 구축하여 사용하고 있었기 때문에 기존 태터 버전 설치하는 것과 거의 동일하게 바로 되었구요.
보실 분들은 http://server.daybreaker.info/tt/daybreaker 로 오시면 됩니다. 다중사용자 형식으로 설치해서 뒤에 식별자가 더 붙어있구요. 아직 사용자 추가를 어떻게 하는지는 모르겠네요. (수동으로 db를 수정하면 되려나.. -_-)
그리고 스킨 경로 문제와 댓글에 댓글 달 때의 버그가 있어 chester 님께 Google Talk로 대화하면서 실시간 테스트 및 버그 리포팅을 하고 있습니다. 그럼~
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
이번엔 인간과 기계 수업 대신 CS101 연습을 째고(물론 미리 실습 문제 풀어서 조교한테 연락해놨다. 다만 지각 처리될 수도 있다고 한다) 첫눈에서 오신 남세동 선배의 세미나를 들으러 갔다. -_-;
원래는 KAIST Google SIG 내에서 세미나를 할 예정이었으나 어찌어찌하다보니 규모가 커져서 다른 사람들도 와서 볼 수 있게 별도로 시간을 잡았다고 한다. 오늘 7시부터 Google SIG 모임이 있다고 하는데, 다른 할 일 때문에 거기까지 가지는 않았다.
세미나 내용은 좁은 의미의 검색 서비스와 넓은 의미의 정보 서비스에 대한 설명, 그리고 구글과 네이버의 비교, 첫눈의 특징, (회사에 관계없이) 기술적으로 채워질 수 없는 부분, 앞으로 도전하고자 하는 것 등이었다.
특히 나의 관심을 끌었던 것은, 구글과 네이버의 비교였는데, 엔지니어 입장에서 봤을 때 분명히 구글이 더 우수한 기술을 사용하고는 있지만, 네이버가 한국에서 성공할 수 있었던 이유는 기술(기계)이 해결해주지 못하는 부분을 인력(일명 알바 -_-)으로라도 채웠기 때문이라는 것이다. 물론 그와 함께 별로 복잡한 기술을 사용하지 않으면서도 '검색' 서비스에 붙여 엄청난 시너지 효과를 낸 지식인도 빠질 수 없었다. 실제로, 나는 구글과 네이버를 서로 다른 용도로 활용하는데, 구글은 정말 웹에 어딘가 꼭꼭 숨어있을 것 같은 그런 정보를 찾는 용도로 쓰고, 네이버는 실생활에서 급히 답변이 필요한 질문들—예를 들면 룸메 컴퓨터가 갑자기 부팅이 안 되면서 메인보드가 삑삑거릴 때—을 찾는 용도로 쓴다. 국내의 유명 사이트나 인터넷에서 회자되는 각종 키워드에 대한 검색도 네이버로 한다.
아직까지, "이상미"로 검색했을 때 그녀의 미니홈피가 검색 결과 상위에 표시되는 것을 단지 PageRank나 SnowRank와 같은 알고리즘만으로는 구현이 불가능하다는 이야기다. 이들은 모두 직접적인 언급이나 링크를 필요로 하는데, 사람들이 그녀에게 관심은 많아도 실제로 링크를 걸거나 하는 사람은 극히 적다는 것이다. 결국 네이버는 각종 정보 소스가 되는 업체(언론사, 전자정부 등)와 제휴하거나 자체 인력을 동원하고 있는 것이다.
한편, 지식인이 검색과 결합하여 지금과 같은 영향력을 가질 수 있었던 것은, 바로 지식인의 특성 자체가 질문과 답변이 명확히 구분되고 제목에 핵심 키워드가 들어간다는 점이다. 지식인과 같은 서비스의 아이디어는 오래 전부터 있었고 꽤 많은 업체들이 서비스를 했었지만, 네이버의 검색과 결합하면서 그 진가가 나타난 것이다. 또한 내가 위에서 예로 들었던 상황이나, "끼기긱"을 검색하면 자동차 브레이크가 고장났을 때의 대처법이 나오는 것과 같은 정보의 생산이 이루어지도록 촉진했다는 데 또한 의의가 있다.
이와는 조금 대조적으로, 구글은 모든 것을 기계가 자동으로 처리하도록 하는 데 목표를 둔다. 따라서 검색 결과의 객관성은 매우 뛰어나지만, 그것이 항상 사람들이 원하는 결과는 아니며, 특히 "무엇이든지 물어보세요" 기계처럼 검색엔진을 대하는 대중들한테는 그다지 맞지 않는다는 것이었다.
여기에 덧붙여, 한국의 초고속 인터넷 보급 상황은 절대 무시할 만한 것이 아니라고 한다. 미국은 인터넷 사용자의 50%가 모뎀을 쓰고 있어서 애초부터 화려한 페이지를 쓸 수 없으나, 우리나라에서는 영화를 검색하자마자 바로 동영상으로 보여줘도 별 문제 없다는 것이다. (물론 이런 검색 결과 또한 사람 손으로 이루어진다) 사실 웹접근성 등의 얘기가 그 자체로서는 도덕적 가치 판단에 잘 맞는 이야기지만, 실제 서비스 개발자 입장에서는 사용자의 대다수를 고려하면 되기 때문이다. 이 부분은 나도 인정하지 않을 수 없는 것이기도 하다. 한국의 Rich Web Design은 외국에서도 관심을 보이고 있지만 그들의 사용자 환경 때문에 선뜻 받아들이지 못하는 거라는 얘기도 있었다. (사실 외국인이라고 해서 텍스트 기반 서비스를 더 좋아한다고 보기는 어렵다)
물론 네이버가 웹표준 문제부터 시작해서, 블로그의 글 삭제나 저작권을 안 지키게 하는 데 도움을 준다는 둥 여러 말이 많은 건 사실이나, 어쨌든 국내의 검색 시장의 동향을 잘 파악하였기에 지금처럼 성공했다고 할 수 있는 거라고 한다.
그러면 첫눈은 무엇을 바라보는 것인가? 위에서와 같이, 네이버는 기계로 할 수 없는 부분을 사람이 직접 하고 있다. 그렇지만 앞으로 계속해서 기술이 발전하면 어느 순간 인간보다 기계가 하는 것이 더 나은 때가 오는데, 그러면 바로 무너지는 것이 네이버라는 것이다. (이는 Semantic Web 등과도 연관이 깊다) 첫눈도 사실 게시판 검색 등을 구현할 때 완전 제각각인 게시판들을 놓고 날짜, 제목, 작성자 등을 추출하기 위해 엄청난 노가다를 하여 수동으로 템플릿을 만들었다고 한다. 현재로서는 기계가 인간을 앞서기까지 시간이 많이 남아보이지만 언젠가는 그렇게 될 것이라는 얘기다. 세미나에서 직접 언급하진 않았지만 첫눈은 궁극적으로는 그런 걸 목표로 하는 것 같았다.
그리고, 첫눈이 과감하게 검색 시장에 뛰어든 것은, 검색이라는 것 자체가 인터넷의 권력이요 허브이기 때문이라고 한다. 인터넷의 방대한 정보는 검색이 없으면 누구도 접근할 수 없을 만큼 너무나 많고, 따라서 검색은 인터넷을 유지시키는 데 필수적인 요소라는 것이다. 업계에서 구글이나 네이버 등이 높은 시가총액을 가진 것도 이것을 반영하기 때문이란다. 그렇기 때문에 가만히 있어도(물론 논다는 뜻은 아니지만) 투자가 들어오고 광고만으로 먹고 살 수 있다는 것이다. (하지만 이에 대해 너무 낙관적인 것 아니냐는 지적도 나왔다)
첫눈은 또한 한국의 인터넷 환경에서만 나올 수 있는 새로운 서비스 아이디어를 찾고 있다고 했다. 얼마 전에 생긴 블로그·홈피 배경음악 검색 서비스인 QBox는 저작권을 합법적으로 지키면서도 무료 음악을 들을 수 있게 해 주는 신개념 서비스라며 첫눈도 이런 새로운 아이디어를 바라고 있다고 했다.
그러면서, 검색이라는 것은 인터넷의 꽃이요 가장 중요한 핵심부라며 첫눈은 바로 거기에 도전하는 것이라고 끝맺었다. (급히 정리하느라 조금 순서가 섞이거나 빠진 부분도 있을 것이다)
이런 내용의 세미나였는데, 2시간 동안 정말 열정적으로 재미있게 잘 들었다. 전에 누군가 말했듯, 아마도 2006년은 세계적으로든 국내로든 인터넷에 대한 인식이 크게 변화하면서 비약적으로 발전할 수 있지 않을까 생각된다.
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
후우. 정말 오랜만에 이 글을 쓰는군요. -_-; 제 블로그 계속 보신 분들은 아시겠지만 그동안 상당히 바빴습니다. 그렇다고 무한정 안 쓸 수는 없으니 계속 진행해야겠지요.
오늘 다룰 내용은 문서의 구조를 잡는 것입니다. 전에도 말했듯 웹페이지는 하나의 문서입니다. 그렇다면 '문서'에 들어가는 논리적인 구조가 어떤 것이 있을까요? 학창시절의 국어 시간으로 돌아가, '글'을 구성하는 요소가 무엇이었는지 생각해봅시다.
- 글
- 제목
- 도입
- 본문
- 맺음말
- 참고 자료
이렇게 나누어질 수 있고 실제 글 내용을 이루는 도입-본문-맺음말은 소제목이 달려 있기도 합니다.
자, 그럼 이걸 XHTML 문서에서는 어떻게 해 줄까요? Heading과 Division을 사용합니다. Heading은 논리적인 제목, Division은 논리적인 문서 의미 영역을 정하는 것을 뜻합니다. 각각은 h1, h2, h3, ...류의 태그와 div, p 태그 등으로 이루어지지요. h? 태그는 제목을, div는 논리적인 영역 구분을, p는 문단 구분을 합니다.
조금 복잡하긴 하겠지만, 지금 보고 계시는 이 블로그의 소스 보기를 해 보십시오. 그러면 어떤 식으로 구성하는지 금방 아실 수 있을 겁니다. (가능하면 메모장보다는, 태그 문법 강조 기능이 있는 AcroEdit나 UltraEdit 등에서 보시는 게 좋습니다)
<body>
<div id="header">
<h1>전체 제목</h1>
</div>
<div id="page">
<h2>중간 제목</h2>
<p>내용</p>
</div>
<div id="sidebar">
<h2>메뉴</h2>
<ul>
<li>메뉴 항목 1</li>
<li>메뉴 항목 2</li>
</ul>
</div>
<div id="footer">
<p>copyright</p>
</div>
</body>
똑같지는 않지만 이런 식입니다. 중간 중간에 들어간 id 속성은 나중에 CSS를 이용하여 실제 디자인을 정의할 때 사용하게 되며, 또한 똑같은 이름의 태그더라도 문서에서 어떤 역할을 하는지 표시해 줍니다. 여기서, id 속성의 값은 이 페이지 내에서 유일해야 합니다. (사이트 전체에서 유일할 필요는 없구요) id 속성은 Javascript로 XHTML 문서 구조에 접근하고자 할 때 고유 식별자로 이용됩니다. 비슷한 기능의 속성으로 class가 있는데 이건 해당 태그가 어떤 부류인지를 나타냅니다. 가령 블로그의 post 들은 여러 개가 나올 수 있고 하나로 분류할 수 있는 공통적인 특성을 가지므로 <div class="post">포스트 내용</div>과 같이 반복되는 경우에 주로 사용합니다.
제 블로그에서 스타일시트를 제거하고 보시면 그 차이를 확 아실 수 있습니다. IE의 인쇄 미리보기를 해 보세요. 그러면 거의 기본 스타일대로 나오는데, heading에 따라 구조가 잘 분리되어 있음을 볼 수 있습니다. (보통 h1은 한 페이지에서 한 번만 쓰이고, 그 하위 제목으로 h2, 또 h2의 하위 제목으로 h3, 이런 식이죠)
어쨌든, class 지정과 id 지정, 그리고 문서 구조를 구분하는 적절한 태그를 사용하면 나중에 CSS로 작업할 때 굉장히 편해집니다. 자기 자신의 상위 태그가 특정 id나 class를 가지는 경우 css에서 바로 접근할 수 있기 때문인데, 이건 추후 따로 다루도록 하겠습니다.
다음 번에는 글 작성 시 주로 사용되는 링크, 글자 속성을 바꾸는 태그들에 대해 알아보겠습니다.
덧/ 보통 줄바꿈을 하기 위해 br 태그를 많이 쓰죠. 그런데 사실 문단의 의미를 살리는 p 태그를 쓰다보면 소스코드를 적는 경우를 제외하고는 거의 br 태그를 쓸 일이 없습니다. br 태그를 최대한 줄여보는 습관을 가지면 XHTML을 구조적으로 짜는 데 조금 더 보탬이 될 것입니다.
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
드디어 지난 밤에 공식 블로그를 통해 현재 진행 상황이 공개되었습니다. 이미 21일부터 저는 몇몇 블로거 분들과 함께 Closed Beta에 참여하고 있었고, 각종 버그나 개선 제안 등을 해오고 있었지요.
그동안 그렇게 오래 기다려온 만큼 태터 1.0은 그만큼의 보답을 하리라 확신합니다. 아직 베타 버전이라 자잘한 버그들이 조금 있지만, XHTML 1.1 완전 준수 및 스킨 하위 호환성 보장(새 버전에서는 카테고리를 ul, li 태그로 쓸 수 있는데 이전 스킨 사용자를 위해서 기존의 table 방식도 지원 등등), Directory Mapping을 이용하여 mod_rewrite나 mod_alias가 있다면 Fancy URL 사용 가능, imazing 및 javascript 기반의 슬라이드쇼 기능 내장, 웹표준을 최대한 준수할 수 있도록 노력한 WYSIWYG 에디터 제공, 그리고 Tatter Guild의 기본 플랫폼인 EOLIN 제공(이것을 통해 태터 센터를 사용자들끼리 만드는 것이 가능해집니다), Tag Cloud 도입(카테고리와 태그를 동시에 사용 가능) 등 엄청난 기능들을 가지고 찾아옵니다.
일단 내부 코어 구조가 완전히 뒤집어졌기 때문에 그동안 써오던 랜덤 포스트 기능 등 태터 소스를 건드려서 고쳐 쓰던 팁들은 모두 무용지물입니다. -_-; 대신! Plug-in 시스템을 지원할 예정이라 합니다. 오늘 아침에 베타 테스트 블로그에 난 것을 보니 기본 시스템은 완성되었으나 당장 베타에 도입하기는 어려울 것이라고 하는군요. 이것이 가능해지면 드디어 일반 사용자들이 태터 소스를 뜯어고칠 일은 없어질 겁니다.
그리고, 전체적으로 태터툴즈의 동작 속도 또한 빨라졌습니다. 클베가 태터 컴퍼니에서 제공하는 곳이라서 그런지는 모르겠지만, 확실히 제 계정에서 돌아가는 것보다 빠릅니다. 실제 비교는 오픈 베타가 진행되면서 설치를 해봐야 알 것 같군요.
아무튼 태터툴즈 화이팅입니다! :D
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
CSS Reboot is complete!
I planned to make two other skins - simple mode and mobile mode with style-switcher - but couldn't do that with not enought time. (Just before 4 days, I've took the mid-term exam.)
Photos used in this skin is contributed by my friend Mingyun, they were taken in Seoul International Fireworks Festival. The skin's concept is also "Fireworks".
In Internet Explorer, the comment and trackback view may not be rendered properly because of IE's many CSS bugs. This skin is tested on Mozilla Firefox and Safari in MacOSX 10.4, and Opera 8.5.
Visitors who came from foreign countries (especially non-Asia) may have to install Asian unicode fonts to see my blogs.
I will appreciate you if you feel comfortable in my homepage. :)
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
지금 제 블로그에 들어오시면 보이는 게 바로 Fireworks 스킨입니다. CSS Reboot 이벤트를 준비하기 위해 제작하고 있으며, XHTML 1.0 Transitional을 완전히 준수하고, CSS 2.0에 기반을 두고 작성하였습니다. (역시나 IE 핵을 안 쓸 수가 없었다는..ㅠㅠ)
사진은 지난 29일 서울 세계 불꽃축제에 갔다온 친구 녀석한테 얻었고(그 녀석이 사진을 잘 찍는 편), 포토샵으로 미리 디자인 컨셉을 잡은 후 png로 저장하여(역시나 IE가 감마 채널을 이상하게 해석해서 또 문제-_-) 작업했습니다. 이 스킨은 제 개인 용도로만 사용됩니다.
원래 두 번째 스킨으로 Style Switcher를 적용하여 simple 모드를 만들려고 했는데 시간 관계상 CSS Reboot 이벤트까지는 준비를 못 할 것 같고, 일모리 님의 이벤트에나 내봐야 할 것 같군요. 아무튼 CSS Reboot 준비하시는 다른 분들도 힘내서 열심히 하시기 바랍니다. :)
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
꽤 오래 전부터, 대략 나모웹에디터가 나올 때쯤부터 위지윅이라는 단어가 대세를 이루기 시작했다. "What you see is what you get." 보는 대로 얻는다는 말인데, 보통 웹에디터나 워드프로세서 등에서 "편집할 때 보이는 것 그대로 결과물이 나온다"는 뜻으로 사용된다.
요즘 들어서, 과연 이것대로 가는 것이 바람직한 방향인가에 대해 고민하기 시작했다. 분명히, 처음 사용자 입장에서는 위지윅이 편하다. 하지만 (특히 웹 분야에서) XHTML의 구조적 특성이나 CSS 기반 디자인 등을 잘 살리려면 위지윅처럼 쉬운 사용 환경을 어느 정도 버려야 한다.
어느 정도는 툴이 해결할 수 있지만, 기술적으로 불가능한 부분이 존재한다. 예를 들어, 정말 근본주의적 입장을 취하면, 웹페이지에서 bold체 글꼴을 쓰는 것조차 그에 맞는 XHTML 태그에 CSS로 디자인을 정의하는 것이 정석이다. 하지만 그렇게 하면 E-Mail을 보냈을 때 보는 환경(웹메일인 경우 특히 더 그렇다)에 따라 bold로 나올 수도, italic으로 나올 수도 있게 된다. 즉, 원래 의도하고자 했던 것과 멀어지는 결과를 낳는다.
현재 gmail의 경우는 <span style="font-weight:bold">를 써서 해결하고 있다. 보통은 <b> 태그를 쓰는 방식일 것이다. 하지만 둘 다 완전히 구조적인 활용이라고 볼 수는 없다.
이러한 맹점도 있지만, 웹표준을 정말 깔끔하게 지키기 위해서는 사용자의 편의성에 반하는 부분이 존재한다. (단순한 웹사이트의 정보이용자가 아니라, 블로그나 게시판처럼 뭔가를 작성할 경우에 말이다) 시맨틱 웹의 입장에서 봤을 때 위지윅이 Web/XHTML 등에 비전문가인 정보생산자들에게 좋은 영향을 준다고 말할 수 있을지는 의문이다.
아직은 자동화된 툴이 알아서 짜 주는 코드보다 사람 손으로 짠 코드 내지는 자동 생성 코드를 손으로 정리해준 코드가 더 깔끔하고 웹의 정신에 부합한다. 코드의 간결성이 꼭 절대적인 가치를 지닌다고 볼 수 있는지의 문제도 있는 데다, 게시판·블로그와 같은 경우는 더더욱 논쟁거리가 된다.
이러한 괴리의 대안으로 위키 문법 등이 있겠지만, 게시판·블로그 사용자에게는 사실 XHTML을 조금 배워서 사용하나 위키 문법을 배워서 사용하나 큰 차이가 없다. 이 상황에서 항상 위지윅으로 가야 한다고만 말할 수 있을까? 기술이 발전하고, 혹은 인공지능이 등장해서 사람이 하는 일을 대신한다면 해결될 수 있는 문제일까? 사용자의 편의성을 최대로 추구해야 하는가, 아니면 보다 근본적인 가치를 위해서 일부 희생해야 하는가? 고민된다.
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
일모리님의 웹표준 이벤트에서는 사용 툴에 의해 표준에 맞지 않는 부분은 심사할 때 고려하지 않겠다고 했었는데, CSS Reboot의 경우는 그것을 외국인들에게 설명하기도 난감하고 해서 일단 카테고리를 없애는 방향으로(....) XHTML 1.0 Transitional만 준수하였습니다. -_-
Tatter Tools 1.0은 도대체 언제 나오는 겝니까!!! ㅠㅠ
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
이제 중간고사도 끝났고, 잠시 동안 여유 시간이 주어졌으니 11월 1일까지 완료해야 하는 CSS Rebooting을 시작하겠습니다. 이미 daybreaker.info 메인 페이지는 공사 상태로 들어갔고, 조만간 이 블로그도 공사 상태로 바뀔 예정입니다. (잘 하면 방명록 부활시킬지도..-_-)
cssreboot.com은 이제 before/after screenshot과 design note를 올릴 수 있게 준비되었습니다. CSS Reboot을 신청하신 분들 모두 힘내봅시다!
* 작업 도중 일부 기능에 문제가 생길 수도 있으니 양해해주시기 바라니다.
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
시험은 시험이지만, 간만에 공들인 프로그램이 하나 나왔기에 적어둔다. Data Structure에서는 Homework와 Programming Project 두 가지로 과제가 나오는데, Homework는 간단한 문제를 푸는 것이고, Programming Project는 하나의 프로그램을 완성하는 것이다. 당연히 프로젝트가 시간이 오래 걸리고 빡세다.
지금까지 3개의 숙제와 2개의 프로젝트가 나왔는데, 두 번째 프로젝트는 SameGame이라는 간단한 게임을 만드는 것이다. 무작위로 3 종류 정도의 공이 배열되어 있으면, 어느 한 공을 클릭했을 때 그 공들과 이어진 다른 공들을 없애고 점수를 얻는 방식이다. 한 열이 다 없어지만 그 열은 오른쪽 공들이 채우고, 공들은 중력이 있는 것처럼 아래로 떨어진다. (애니메이션이 아니라 중간에 공이 없어지만 거길 메꾼다는 뜻)
같은 공끼리 없어지는 거야 뭐 recursion으로 어렵지 않게 구현했는데, 보너스 점수로 나온 additional features-_-... 원래는 조금만 하려고 했었으나 역시 돌돌돌돌 말리면서 결국...
다운로드 (binary only, .exe로 포팅한 것, JVM 1.5 이상 필요)
소스코드 다운로드 (GNU GPL)
대략 빨강, 파랑, 초록 공이 흰 바탕에 fillOval로 그려져 있던 걸 이 수준으로 만들어버렸던 것이다. 마우스 포인터를 움직임에 따라 같은 종류의 공들이 그룹으로 하이라이트되는 것도 구현했다. -_- (이게 가장 노가다였다) 거기다 텍스트 파일에 저장되는 간단한 랭킹과 게임 옵션창도 구현했으며 모두 Swing을 사용한 GUI다.
오랜만에 공들여서 만들었더니 심심풀이로 아주 제격인 게임이 나왔다. (이러다가 시험 기간에 여기에 말리면 곤란) 어쨌든 Java로 만든 것이니, 나중에 기회가 되면 한 번 애플릿으로 포팅해서 웹에 공개해보도록 하겠다. -_-;;
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
요즘에 악보를 그리는 프로그램에 대해서 관심이 많이 있었고, LaTeX를 배워볼까도 생각하고 있었다. 그러던 차에, IRC에서 그 유명하신(-_-) 경곽 19기의 서 모 선배를 만났고, 그 분이 lilypond라는 프로그램이 있다는 걸 알려주셨던 것이다. -_-;;
일단 홈페이지 가서 개발 동기와 목적, 스크린샷 등을 보니 품질이 상당히 훌륭하길래 한 번 써보기로 했다. (그러나 그것이 삽질의 전주곡이 될 줄은....-_-)
전에 MusiTex의 스펙 문서를 한 번 봤던 터라 기본 구조를 이해하는 건 그리 어렵지 않았다. 그래서 연습 겸(;;;) 스캔이 잘못되었던 Antonio Diabelli의 6 Sonatas for 4-hands 중 1번 1악장 첫 두 페이지를 만들기로 했다.
Phase 1.
일단 원하는 음정을 그려보는 것이 문제였다. 절대 음정으로 모두 쓰려니 곡 자체가 음역이 넓어 불편할 것 같아 relative 명령을 사용했더니 깔끔하게 해결되었다. 기본적인 tie, slur, 화음, 음길이, 스타카토, dynamics 등을 넣는 방법을 익혔다. 여기서 가장 고생했던 것이 화음 넣는 방법을 익히는 거였는데, 알고보니 나는 제대로 넣고 있었지만 다른 부분에 오류가 있었다. -_-;
Phase 2.
내가 원하는 위치에 원하는 요소를 놓는 방법을 찾았다. Vertical spacing, TextScript, Rehearsal Mak, Metronome Mark 등을 원하는 대로 놓으려고 보니 각각마다 설정하는 방법이 제각각이었다. 이 과정에서 엄청난 시간이 소요되었는데, lilypond의 매뉴얼 전체 중 70% 가량을 최소한 한 번 이상 보았다. -_-;;
Phase 3.
lilypond 엔진에 문제가 있음을 발견. 악보 그리기 자체의 문제라기는 아니었고, postscript로 컴파일 도중 아주 사소한 문법 오류가 생겼을 때 에러 메시지를 출력하지 않고 parsing하다가 그냥 종료되어 버리는 경우가 있었다. 이게 소스가 아주 복잡하기 때문에 에러 메시지가 없으면 어디가 잘못됐는지 찾기가 상당히 어렵다. 따라서 새로운 명령어를 사용할 때마다 애를 먹었다. (특히 #과 를 바꿔서 쓰는 경우에 이런 현상이 잘 발생-_-)
Phase 4.
내가 만든 것과 원래 종이 악보와 레이아웃을 동일하게 맞추기. 이건 이미 NWC에서도 비슷하게 해 본 삽질이었는데, 매번 "컴파일"이라는 과정을 거쳐서 pdf로 결과물을 확인해야 하기 때문에 시간이 오래 걸렸다. 악보 전체의 글꼴 크기, system 사이 간격, staff spacing 등등 온갖 변수를 아주 '잘' 조절해서, 결국 강제 pageBreak까지 써가면서 맞추었다. 이거 하는 데 대략 1시간 이상 소요되었다. -_-;
이게 처음과 마지막에 레이아웃을 잡기가 힘들어서 그렇지 음표를 입력하는 건 그렇게 어렵지 않으므로, Secondo 악보는 나중에 금방 끝낼 수 있을 것이다. (그렇다. 지금까지 한 삽질은 바이엘 수준으로 간단한 primo 악보였던 것이다! orz) 다행히, 내가 작곡한 악보들의 높은 품질로 만들 때도 요긴하게 쓰일 것 같다.
어쨌든 이렇게 해서 오늘의 삽질 일기는 끝. -_-
덧. 삽질을 많이 하긴 했지만, 매뉴얼을 통독한 덕분에 다양한 악보 표기에 대해 알 수 있었다. 작곡할 때나 다른 악보를 볼 때 도움이 많이 될 것 같다. (이 프로그램은 그레고리안식으로 표기된 것도 지원하며 옵션에 따라 음악 교과서에 나오는 박자표도 만들 수 있고 무궁무진하게 응용 가능하다. 게다가 LaTeX에 확장으로 바로 삽입 가능!)
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
나는 노트북을 쓰기 때문에 보통 전원을 끄고 다시 부팅하는 대신 최대절전모드를 애용한다. 근데, 이게 굉장히 편한 기술이긴 하지만 가금 매우 불안정할 때가 있어(특히 프로그램을 여러 개 띄운 상태일 때) 복구 불능이 되는 경우가 있다.
숙제한 걸 인쇄하려고 켰는데, 웬걸 작업표시줄이 먹통이 되기 시작하더니, 탐색기에서 파일을 열려고 하면 죄다 먹통이 되는 것 아닌가. 다행히 숙제 파일을 열어두고 최대절전모드로 갔었기 때문에 인쇄는 할 수 있었다. 하지만 Flash, Word, Hwp, Firefox, Internet Exploreer, Notepad, gVim, cygwin 등등이 모두 떠 있던 상태여서 그랬는지-_- 작업관리자마저 멈추는 현상이 발생했다. 이 와중에도 mIRC는 잘 작동하여 사람들과 이 난감한 상황에 대해 이야기(?)를 하고 있었다.
나는 VB와 IIS, PHP를 써서 내 스크린샷을 찍어 내 노트북의 ip 주소로 접속하여 볼 수 있게 해 놓는다. IRC에서 대화할 때 자주 써먹는데, 이번에도 에러 상황을 이야기할 때 써먹고 있었다.
그런데 웬걸, 엉뚱하게도 Firefox 버그를 발견했다. 탭이 여러 개 열린 상태에서 Firefox를 닫으려고 하면 종료하겠냐고 물어보는데, 그 상태에서 IRC에 뜬 URL을 더블클릭하여 새 탭이 추가되나까(원래는 modal 대화상자라 사용자가 firefox 창을 조작할 수는 없다) cancel 버튼을 눌렀는데도 종료되어 버렸다. (참고로 Firefox 1.5 Beta 2를 쓰고 있다)
결국 Windows가 에러난 덕분에 Firefox 버그를 발견했고 바로 Bugzilla에 올려놓았다. 도대체 숙제 하나 뽑으려다가 뭐 이렇게 말려버렸는지..-_- orz
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
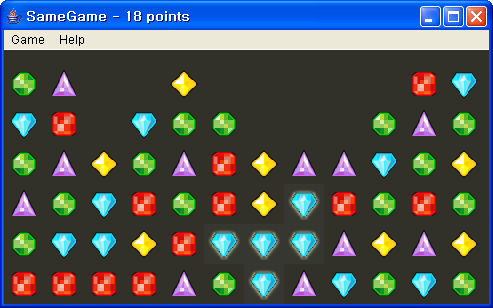
Hello, World!
갑자기 난데없는 "Hello, World!"냐구요? 보통, 새로운 프로그래밍 언어를 배울 때 가장 먼저 하는 것이 이거랍니다. 그 프로그램 언어의 가장 기본적인 문법과 실행 구조를 가지고 저 문구를 출력하는 것이죠.
XHTML은 비록 프로그래밍 언어라고 할 수는 없지만, 어쨌든 컴퓨터 세계에서 사용되는 언어이므로 이걸 해보도록 하겠습니다.
<!DOCTYPE HTML PUBLIC "-//W3C//XHTML 1.1//EN"> <html> <head> <meta http-equiv="Content-Type" content="text/xhtml; charset=euc-kr" /> <title>XHTML 연습</title> </head> <body> <p>Hello, World!</p> </body> </html>
메모장에서 이렇게 쓴 후, test.html 이라는 이름으로 저장해 보세요. (주의하실 것은 저장 대화상자에서 "파일 형식"을 "모든 파일"로 하셔야 합니다. 그래야 확장자가 제대로 붙습니다) 그리고 인터넷 익스플로러로 열어 보세요. 탐색기에서 더블클릭!
소스를 이해하진 못하셨더라도, 일단 저렇게 보이나요? 그러면 된 것입니다.
그러면 이제 소스를 읽어봅시다. 첫 번째 줄은, 이 문서가 어떤 버전의 규약을 사용하는지 나타냅니다. XHTML은 현재 1.1 버전까지 개발되었고, 이것이 가장 최신 표준입니다. 지금은 그 정도만 알아 두시고, 나머지는 그냥 그렇다고 알아두시면 되겠습니다. (이걸 쓰지 않을 경우 웹브라우저가 HTML 4.01 Transitional로 해석하는데, 문서를 화면에 보여줄 때 차이가 생겨 깨질 수 있습니다)
그 다음에는 본격적으로 태그가 나오기 시작합니다. 태그는 XHTML 문서의 소스를 봤을 때 꺽쇠(<, >)로 둘러싸여 있는 것들을 말합니다. <html>, <head> 등등이 모두 태그지요.
그런데, 컴퓨터는 사람보다 좀 덜떨어져서-_- 태그를 시작했으면 어디서 끝나는지 알려줘야 합니다. <xxx>로 시작했다면 </xxx> 라고 닫아줍니다. 여는 꺽쇠 뒤에 slash(/)를 붙이고 태그 이름을 적고 꺽쇠를 적습니다. 위의 소스에서 보시면 html, body, title, p 태그가 이렇게 쓰여 있습니다.
html 태그는 문서 전체를 둘러싸는 태그이며, 다른 모든 태그는 html 태그 안에 들어있어야 합니다. (물론, xhtml 규약 버전을 지정하는 DOCTYPE 지시자는 예외이고, 나중에 설명할 comment 태그도 밖에 둘 수 있습니다) 반드시 head 태그와 body 태그를 갖춰야 하며, head 태그는 title 태그를 가지고 있어야 하지요. (이렇게, 상위-하위 관계로 이어지는 구조를 "Tree 구조"라고 부릅니다. 윈도우의 폴더 구조와 같습니다.) 그러면 최소한 XHTML 문서라고 부를 수 있게 됩니다.
자, 이제 여러분을 혼란스럽게 하는 소스가 등장합니다. 네 번째 줄의 meta 태그인데요, 저게 도대체 무엇을 하는 걸까요? -_-; 일단 당장은 알아두실 필요가 없습니다. 다만, 이 페이지를 웹브라우저로 열었을 때 글자들이 깨지지 않고 제대로 보이게 하기 위한 거라고만 알고 계시면 됩니다.
그 밑의 title 태그는 브라우저의 제목표시줄에 보이는 제목을 지정합니다. 스크린샷과 소스를 보시면 알 수 있겠죠. 그리고 body 태그는 브라우저의 문서 표시 영역 안에 들어가는 내용들이 들어갑니다. 여기에 글도 들어가고 사진도 들어가고 링크도 들어가고.. 거의 모든 내용이 들어갑니다. (나중에 설명하겠지만 head 태그 안에도 다른 태그들이 더 들어갈 수 있습니다)
body 안에 있는 p 태그는 문단을 만듭니다. p 태그로 묶은 내용은 말 그대로 문단이기 때문에, 여러 개의 p 태그가 한 줄에 있더라도 알아서 분리됩니다. (태그를 닫았을 때 자동 줄바꿈이 됩니다) 이렇게 장황하게 설명했는데, 아래의 문법 규칙을 앍고 나면 다음부터는 간단히 설명해도 충분히 알아들으실 수 있을 것입니다.
XHTML의 문법
아까 말씀드렸듯이, 첫 줄에는 반드시 DOCTYPE 선언 지시자가 들어가고, html 태그가 문서 전체를 둘러싸며, head, title, body 태그는 반드시 있어야 한다고 했습니다. 또한 태그를 닫을 때는 /를 붙인다고 했었죠. 그 외의 규칙을 좀더 알아보겠습니다.
1. tag
태그는 기본적으로 열었으면 닫아야 합니다. 보통은 위에서 설명한 대로 태그 이름 앞에 /를 붙이지만, 소스의 meta 태그처럼 사이에 들어갈 내용이 없어 태그 그 자체 하나로만 쓰는 경우가 있습니다. 그럴 때는 여는 태그의 닫는 꺽쇠 바로 전에 /를 붙입니다. 나중에 설명할, img, br, meta, link 태그 등이 이에 해당합니다.
2. attribute (속성)
위 소스에서, meta 태그 안에 들어있는 내용들이 meta 태그에 대한 속성들입니다. http-equiv, content는 속성 이름이고, "Content-Type", "text/xhtml; charset=euc-kr"은 각각에 대한 속성값입니다. 속성이 있으면 반드시 속성값도 있어야 합니다. (즉 <meta http-equiv content= />와 같은 건 허용되지 않습니다. 그리고 각 속성값에는 반드시 쌍따옴표(")를 붙여야 합니다. 컴퓨터를 다뤄보신 분들 중에, 문자열만 쌍따옴표를 붙이고 숫자 등에는 안 붙인다고 생각하시는 경우가 있는데 XHTML에서는 무.조.건. 다 붙입니다.
아, 그리고 이 속성들은 여는 태그에만 쓰면 되고 닫는 태그에 또 쓸 필요가 없습니다. (실은 쓰면 안 됩니다. -_-)
3. whitespace
메모장에 소스를 쓸 때, 공백 문자들(스페이스, 탭, 엔터 등)을 보통 whitespace 라고 부릅니다. XHTML에서, 태그와 태그 사이에 있는 whitespace들은 모두 무시되는데, 몇몇 예외가 있습니다. 각 줄의 첫번째가 아닌, 1개씩 따로 떨어져 있는 공백 문자들은 유효합니다. 즉 문장 중간에 들어간 공백들은 그대로인데, 두 개 이상의 공백은 하나로만 인식합니다. 만약, p나 br 태그를 쓰지 않고 여러 줄에 걸쳐서 글을 썼을 경우 줄바꿈 없이 다 붙어나오게 되죠.
br 태그는 순수하게 줄바꿈 기능만을 수행합니다. 그리고 위에서 설명했듯이 닫는 태그가 합쳐진 형태입니다.
4. comment
지금이야 별 문제 없겠지만, 매우 복잡한 문서를 작성할 경우, 태그들만으로는 어디가 어딘지 분간하기 어렵습니다. 그럴 때는 화면에 표시되지도 않고 아무런 역할을 하지 않는 comment 태그를 사용합니다.
<!-- 아무 설명이나 넣으세요 -->
이런 형식으로 사용합니다. 저 사이에는 심지어 줄바꿈이나 태그가 들어가 있어도 싹 무시됩니다. 나중에 설명하겠지만, 이 comment 태그를 조금 다른 목적으로 활용하기도 합니다.
*
일단 여기까지 읽어보셨다면 다음 회부터는 수월하게 나갈 수 있습니다. 사실 시중에 나와있는 책들도 이런 기본 문법을 설명하고는 있지만, XHML과 HTML이 문법에 차이가 있어서 그걸 가지고 그대로 여기에 적용하시면 안 됩니다.
후우~~ 길었습니다. -_-; 끝까지 읽어보시지 못했더라도 가장 기본적인 내용이므로 숙지하셨으면 합니다. (계속 진행될 강좌의 내용을 보면, 여기서 장황하게 설명했던 것들이 어떤 걸 말하는 거였는지 자연스레 알게 되실 겁니다)
- Response
- You can track responses via RSS / ATOM feed
- Posted
- Filed under 컴퓨터
음.. 인터넷을 돌아다니다 보면 "초보를 위한 인터넷 강좌", "HTML 태그 배우기" 등의 자료들을 많이 볼 수 있습니다. 그러나, 그 중에서 제대로 된 XHTML을 알려주는 건 거의 전무하다시피 하죠. 그래서 초보자들을 대상으로 하는 XHTML 강좌(라고는 하지만..-_-)를 해볼까 합니다.
여기서 초보자라고 하는 것은 기본적으로 Windows를 사용할 수 있으며, 인터넷 익스플로러를 쓸 수 있는 정도를 말합니다. 프로그래밍이라든가, Firefox라든가 그런 거 전혀 모르는 상태에서 시작하지요.
제가 바쁘기 때문에 정기적으로 항상 못 올릴 수도 있고, 부득이하게 내용을 더 충실하게 하지 못할 수도 있지만, 조금이나마 이렇게 시작하면 보다 많은 사람들에게 도움이 되지 않을까 합니다. (저도 아직 XHTML에 대해서 아주 깊이있게 알지는 못합니다. 하지만 제가 아는 것이라도 조금씩 공유하다 보면 더 많은 효과를 얻을 수 있겠죠. 혹시 틀리거나 이상한 부분이 있으면 바로바로 코멘트 달아 주시기바랍니다.)
HTML은 들어봤는데 XHTML은 뭐지?
이 블로그에서 XHTML은 키워드로 지정되어 있는 단어라서, 그 단어를 클릭하면 설명이 뜨지요. 그러나 제가 위에서 말한 정도의 독자분이시라면 아마 무슨 소린지 잘 모를 겁니다. -_-;
인터넷을 돌아다니면 수많은 웹사이트(naver, daum, 각종 게임 사이트, 커뮤니트 등등)들을 볼 수 있습니다. 혹시 인터넷 익스플로러에서 오른쪽 버튼을 눌러 "소스 보기"를 해 보신 적이 있나요?
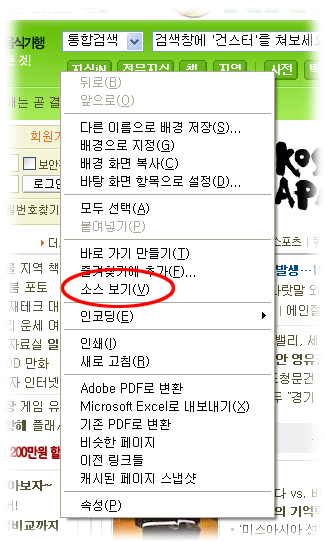
(그림을 오른쪽 버튼으로 클릭하시고 "그림 보기"를 누르면 원래 크기로 보입니다.)
소스 보기를 하면 메모장이 뜨고 그 안에 엄청나게 많은, 전혀 알 수 없는 영문 코드들이 보일 겁니다. 그게 바로 HTML 혹은 XHTML 코드죠. 즉 HTML/XHTML은 웹페이지를 만드는 데 사용되는 일종의 언어 규약입니다.
컴퓨터가 사람이랑 달라서, 아주 정확하게 딱딱 들어맞는 문법을 지켜야 합니다. 다행히, XHTML의 문법은 그리 어려운 편이 아닙니다. (다음 회에 자세히 다루도록 하죠)
여기서 잠깐! - 정작 중요한(?) HTML과 XHTML의 차이에 대해서 설명 안 해줬잖아~
네네.. -_-; 사실 HTML과 XHTML이 따로 나누어지게 된 배경 역사를 설명하면 매우 깁니다. 그걸 다 설명하는 건 무리고, 간단히 HTML의 차세대 버전이 XHTML라고 생각하시면 됩니다. 사용할 수 있는 태그도, 만들어진 목적도 다르죠. (물론 "하이퍼텍스트"라는 링크 개념을 구현하고 정보 전달을 한다는 궁극적인 목적은 같지만요)
조금 더 알고 싶으신 분들을 위해 약간 어렵게 설명하자면, 기존의 HTML은 화면에 보여지는 모양(layout or design)과 문서가 담고 있는 내용(contents)이 구분되지 않는 형태입니다. 나중에 나올 font 태그 등은 글자 모양을 지정하는 태그인데 동시에 내용과 함께 들어있죠. 예전에는 이래도 별로 문제가 없었는데, 인터넷이 발전하면서 동적인 웹페이지가 필요해졌습니다. 그런데 웹페이지를 생성하는 프로그램을 짜다보니, 내용과 디자인이 합쳐져 있어서 매우 불편하더라는 겁니다. 디자인은 일관되게 유지하면서 내용만 계속 바꾸자니, 태그 구조가 복잡하면 프로그램을 짜기가 어려웠던 것이죠.
혹시, 이미 HTML을 조금이라도 다뤄보신 분들은 table 태그를 아실 겁니다. 보통 table을 이용해서 문서의 틀을 짜는데, 모양이 복잡해지고 내용이 많아질수록 소스가 엄청나게 복잡해진다는 것을 경험해보셨을 겁니다. XHTML을 "제대로" 사용하면 그런 일을 피할 수 있지요!
XHTML은 문서의 내용과 구조만을 담고 있습니다. 그럼 디자인은 어떻게 하냐구요? CSS라는, 디자인만을 위해서 만들어진 언어 규약이 또 있습니다. (이것도 키워드인데, 클릭하면 역시나 알 수 없는 말들이...-_-) 하여간, 길게 주절주절 말했는데, 기본적으로 XHTML은 HTML의 차세대 버전이며 인터넷에서 웹사이트·웹페이지를 표현하는 데 사용되는 일종의 언어 규약이다라는 점만 알고 넘어가시면 되겠습니다.
- Response
- You can track responses via RSS / ATOM feed