- 출장 공지 2
- Seven Life 12
- LilyPond 6
Daybreakin Things
올해 봄학기 마지막으로 조교를 맡았을 때 개강 전날 교수님과 한 학기 커리큘럼을 의논하면서 했던 이야기이기도 하고, 내가 전산학을 공부 + 연구해오면서 느낀 부분들이라 따로 글로 정리해본다.
시스템을 설계하는 건 복잡성을 해결하는 과정이다.
내 학번부터 KAIST 전산과의 졸업필수과목이 된 CS408 전산학 프로젝트(Capstone Project) 과목에서는 학생들이 팀을 이뤄 한 학기 내내 그 동안 배운 모든 지식과 기술을 동원하여 '적절한 수준의 복잡도를 지닌' 시스템을 설계·구현한다. 내가 이 과목을 수강했을 때 가장 불만이었던 부분은 과연 얼마나 복잡해야 하는가에 대한 기준이 매우 주관적이었다는 것과, 실제로 그러한 복잡성을 해결하면서 시스템을 설계하는 방법에 관해서는 거의 강의가 이뤄지지 않았다는 점이다. CS350 소프트웨어 공학개론 과목에서 모듈화의 개념이라든가 decoupling의 중요성 등 기초적인 원리를 일정 부분 가르쳐주기는 하지만, 실제로 프로그램을 작성할 때 이를 어떻게 적용해야 하는가에 대한 실전적인 지식은 거의 알려주지 않는다.
이때 채우지 못한, 시스템 설계를 어떻게 "잘" 해야 하는가에 대한 목마름이 내 대학원 생활에서도 상당히 아쉬움으로 남는 부분이라는 걸, 좀 늦게 깨달았다.
내 연구 주제인 패킷 처리 시스템 정도면 "매우 많이" 복잡한 시스템이라고 할 수 있다. 목표는 고성능 패킷 처리 프레임워크를 Linux 기반 환경에서 GPU와 갈은 보조프로세서를 활용해 구현하고, 여기에 CPU와 GPU로 패킷을 잘 배분해서 어떻게 하면 최적 성능에 다다를 것인가에 대한 문제를 푸는 것이다. 나는 사용자들이 새로운 패킷 처리 모듈들을 손쉽게 구현하고 추가·삭제할 수 있게 해야 한다고 보았기 때문에, 단순히 특정한 종류의 application만 동작하는 prototype 프로그램이 아니라 어느 환경에서나 configuration만으로 프로그램 수정 없이 돌릴 수 있는 framework로 만들려고 했고 이를 위해 복잡도가 매우 올라갔다.
예를 들면 어떤 모듈을 실행할 것인지에 관해서는 Click configuration language를 모방한 별도의 DSL(domain-specific language)로 작성된 설정 파일이 있고 이를 해석하는 parser가 달려있으며, 어떤 하드웨어 리소스를 사용할 것인지에 대해서는 embedded Python interpreter를 이용해 직접 시스템 정보를 전달해주고 사용자가 작성한 Python 스크립트가 자동으로 설정하게 했다. 네트워크 카드로부터 패킷을 입력받아 각 모듈들의 CPU 버전 코드를 실행하고 패킷을 출력하는 worker thread들이 여러 CPU 코어를 사용해 돌아가고 GPU를 사용할 필요가 있다고 판단한 경우 패킷들을 모아서 GPU 전담 thread로 보내고 실제 GPU 관련 코드를 실행해주는 부분도 있다. 이 모든 과정은 polling과 event-driven model을 혼합하여 작성한 것이며 병렬화와 batch 처리의 효율성을 모두 극대화하는 것을 목표로 코드를 작성했다.
가장 아쉬웠던 부분은, 어떻게든 프레임워크를 돌아가는 상태로 만들어서 논문을 써놓고 나니, 추상화와 동작 여부 사이에서 trade-off가 너무 많았고(논문을 쓰려면 당연히 최소한 '돌아는 가야' 하니까) 추상화는 결국 내 스스로도 100% 만족하기 힘든 상태가 되어버렸다는 점이다. 처음에는 논문 내용 자체를 framework의 우수성(?)으로 썼다가 여러 차례 학회에 재도전한 끝에 CPU/GPU load balancing 알고리즘을 중심으로 쓰고 framework는 들러리만 서는 형태로 논문을 제출하고 말았다. 그 이유는 '남들이 다 해놓은 거 짜집기한 것 아니냐'라는 내부 피드백을 넘어설 수가 없었고, 넘어설 수 없었던 이유는 설계 결과만 늘어놓는 것이 아니라 왜 좋은가에 대한 설명을 충분히 잘 드러나게 할 만큼 writing skill이 좋지 못함과 동시에 현실과 타협한 부분들이 너무 많았기 때문이다.
사실 이게 바로 내가 대학원에 온 후로 계속 고민하고 힘들어했던 부분이다. 지금 생각해보면, 이를 '새로운' 시스템 설계라고 논문의 형식으로 "잘" 주장하는 방법과 논문으로 썰을 잘 풀 수 있게 처음부터 고민하면서 시스템을 설계하는 방법을 나도 모르고 연구를 도와준 선배도 모르고 교수님도 잘 모르셨던 것 같다. (혹은 선배나 교수님은 경험을 통해 알고 있었더라도 그걸 남도 할 수 있게 전달하는 방법을 몰랐거나.) 실제로 코드를 작성하면서 세밀하게 내린 여러 결정들을 다시 머릿속에서 끄집어내서 왜 그게 좋은지 이유만 잘 붙여도 꽤 그럴싸해보일텐데, 문제는 코드를 '돌아만 가는' 것을 목표로 작성하다보니 이유를 충분할 고민할 시간 없이 작성한 legacy가 너무 커져버렸고, 논문을 실제 쓰는 시점이 되어서야 그런 legacy들에 대한 근거를 찾다보니 시간이 부족하고... 이런 악순환이 반복되며 시간을 너무 끌었다.
교수님과 개강 전날 책상에 네트워크·분산 시스템 분야의 여러 대가들이 써놓은 교과서를 주욱 늘어놓고 목차를 보면서 이번 학기 강의에는 어떤 내용들이 들어가야 할까 고민할 때, 눈에 딱 띄는 책이 있었다. MIT의 Jerome H. Saltzer 교수와 Fraans M. Kashoek 교수가 쓴 Principles of Computer System Design: An Introduction. 책 내용을 자세히 읽어보지는 못했지만 그냥 목차만 봐도, 첫 챕터 첫 문단만 봐도 눈물이 나더라. 왜 이런 걸, 이렇게 체계화해서 알려주는 사람이 없었는가 안타까워서 말이다. 오죽했으면 교수님께도 CS408이 이런 내용을 가르치도록 개편되었으면 좋겠다는 건의사항을 그 자리에서 드렸을 정도다.
나의 안타까움은 여기서 다음 질문들로 바뀐다:

얼마 전 오랜만에 텍스트큐브 코드를 보던 중 inureyes님과 했던 얘기다. 내가 명색이(...) 텍스트큐브 개발자인지라 다른 블로깅 도구로 갈아타기가 좀 그렇고 그런데, 요즘 Octopress 같은 static page 기반의 블로깅 도구들이 좋아보이더라고 얘기했더랬다. inureyes님은 '결국 15년만에 제자리로 돌아왔군요.'라는 한 마디로 대답. 그 말을 들으니 지난 역사가 떠올라 한번 정리해야겠다 싶었다.
대략 15년 전이면 2000년, 내가 중학교 1학년일 때다. 당시 우리나라에는 막 ADSL이 보급되고 있었고, 너도나도 홈페이지 하나쯤 만들어 운영하는 것이 유행이었다. 어찌어찌 HTML 공부해서 x-y.net이란 웹호스팅 서비스에 가입하고 매번 업데이트가 있을 때마다 나모웹에디터로 직접 HTML을 편집해서 올리곤 했다. 그때만 해도 사용자가 올리는 컨텐츠를 홈페이지에 반영해주는 CGI 같은 건 상당히 어려운 기술이었고(PHP도 대중화되기 전이었음) 방문자 수 카운터, 게시판, 방명록 등을 gif/frame/iframe 형태로 홈페이지에 삽입해주는 서비스들이 많이 있었다. 대표적인 게 superboard.com으로, 아기자기한 게시판 템플릿도 여러 종류 제공하고 게시물 목록의 배경색을 그라데이션 느낌이 나게 줄마다 색깔을 다르게 넣어주는 게 일종의 최신 트렌드였다. 오랜만에 생각나서 찾아보니 구글 캐시에 일부 흔적이 보이고 회사는 망한 듯. 그때를 살펴보면 메인 컨텐츠는 홈페이지 운영자들이 직접 HTML로 만들어 올리고, 아무래도 관리나 구현이 귀찮은 상호작용 기능들을 외부 서비스에 의존하던 형태였다.
그러다가 PHP가 웹프로그래밍 언어로 뜨기 시작하고, 웹호스팅들이 MySQL 서비스를 보편적으로 제공하게 되면서 2005년 무렵에는 설치형 도구들이 대세가 되었다. 특히 제로보드가 크게 유행하면서 홈페이지를 만들려면 반드시 써야 하는 도구란 위상을 가졌던 시절이었다. 텍스트큐브의 전신인 태터툴즈가 나온 것도 2005년이고, 오픈소스 프로젝트로 가동되기 시작한 것이 2006년 4월이었다. 워드프레스도 비슷한 시기에 오픈소스 프로젝트로 출발했다. 2007년 무렵부터 UTF-8 인코딩이 대세가 되었고, Firefox 사용자가 늘고 웹표준, Open API가 화두가 되면서 태터툴즈·텍스트큐브와 같은 블로깅 도구들은 OpenID 지원, 트랙백 지원, 스팸 차단 서비스 등을 추가해나가며 점점 CMS에 가까운 형태로 진화했다.
2007년 무렵부터는 블로깅 도구들이 크게 두 갈래의 길로 나누어졌다. 하나는 계속해서 오픈소스 프로젝트로 가동되며 사용자가 직접 자신의 호스팅에 설치해서 사용하는 설치형 방식과 다른 하나는 약간의 기술적 지식을 요구하는 설치형에 비해 가입만으로 쉽게 사용할 수 있는 가입형 방식이다. 우리나라에서는 네이버 블로그와 티스토리가 가입형의 대표주자였고 해외에서는 구글이 인수한 blogger.com과 워드프레스 개발자들이 직접 서비스화한 wordpress.com이 대세였다. 이때의 블로깅 도구들은 점점 세세하고 복잡한 기능을 탑재하면서(예: 웹브라우저에서 직접 사용하는 스킨 편집기) 한편으로는 진입 장벽이 높아지는 문제점도 보여주었다. 2008년 9월에는 태터툴즈와 텍스트큐브를 함께 개발하고 서비스화했던 태터앤컴퍼니가 한국 스타트업으로는 최초로 구글에 인수되었고 약 1년 간 textcube.com 서비스를 유지한 후 blogger.com으로 흡수되었다.
그러다가 2009년 11월 한국에 아이폰이 출시되고 2010년부터는 모바일웹이 대세가 되기 시작한다. 초반에는 데스크탑의 기능들을 그대로 옮기거나 혹은 아예 축소해서 정말 뷰어 용도로 쓰는 방식을 취하다가, 모바일 웹브라우저 기술이 무르익기 시작하면서는 데스크탑과 동일한(그러나 작은 화면 크기와 터치 인터페이스 최적화된) 사용자 경험을 추구하는 반응형 웹디자인이 뜨기 시작했다. 이때부터는 점점 복잡해져만 가던 웹 디자인이 미니멀리즘으로 회귀하기 시작했고 그 트렌드는 2014년 현재도 여전히 진행 중이다.
홈페이지를 만드는 방식도 많이 바뀌었다. 특히 GitHub에서 프로젝트 소개 페이지를 운영할 수 있는 static page 호스팅을 제공하자 static page들을 쉽게 관리할 수 있는 Jekyll과 같은 도구가 나오고 이를 응용한 Octopres와 같은 블로깅 도구까지 등장한 것이다. 사실 개인 홈페이지에서 자신의 글이나 컨텐츠를 보여줄 수 있는 공간과 사용자들의 코멘트나 방명록을 받을 수 있는 공간 정도만 있으면 되는데, 기존의 설치형 블로깅 도구들은 CMS를 추구하면서 지나치게 복잡해져 있었다. 사람들은 생각보다 단순해서 오히려 기능이 많아지면 잘 못 쓴다. 그런 역효과가 다시 static page 기반의 홈페이지로 회귀하는 트렌드를 만든 것이다. 게시판이나 방명록의 위치는 SNS 계정을 활용해 댓글을 남길 수 있는 Disqus와 같은 서비스들이 차지하였다. 결국 15년 전과 똑같아진 것이다. 물론 세부사항을 들여다보면 지금은 15년 전과는 많이 다르다. Open API라는 흐름을 거치면서 서비스 간의 인증이나 연동이 보다 강화되었고, AJAX 기술을 통해 외부 서비스이지만 마치 그 웹사이트의 일부인 것처럼 동작한다.
설치형 도구들은 그 자체로 모든 사용자가 원하는 기능을 최대한 넣는 것에 집중해왔다. 바로 자기완결성을 추구했던 것이다. 반면, Open API와 AJAX 기술은 하나의 웹사이트가 여러 서비스의 조합(composition)으로 만들어지는 기반을 제공하였고, 각각의 전문화된 서비스를 이용해 원하는 목적으로 가공하도록 해주었다. 이것이 바로 분산화·전문화다. 15년의 사이클을 돌고 돌아 이 두 트렌드가 엎치락 뒤치락 했듯이, 컴퓨터의 발전 역사도 중앙집중식 메인프레임에서 개인화·분산화된 PC 환경으로 왔다가 다시 중앙집중식 클라우드로 가는 모양새를 볼 수 있다. 클라우드도 기존의 메인프레임으로는 상상할 수 없던 대규모 스케일을 제공한다는 점에서 큰 흐름은 반복되었지만 똑같지는 않다. 마찬가지로 분산화된 서비스도 그 흐름은 반복되었지만 그 연결은 훨씬 긴밀해졌다.
inureyes님이 이어서 했던 이야기는 여러 주체의 서비스를 모아서 무언가를 구축하면 그것이 많이 쪼개져있을수록 시스템 전체의 불안정성이 올라간다는, 다분히 물리학자다운 이야기였다. A, B, C, ... 서비스를 엮어서 홈페이지를 만들었는데 그 중에 하나라도 동작하지 않는다면 홈페이지는 완전한 서비스를 제공할 수 없게 되는 것이다. 하나에만 의존할 때보다 여러 개에 의존할 때 각각의 실패 확률이 동일하다면 여러 개에 의존할 때 당연히 전체 실패 확률이 올라간다. 서비스의 분산화와 반대인 데이터의 중앙집중화는 정 반대의 문제를 야기한다. 모든 것이 클라우드에 있는 상황에서 내 데이터가 있는 데이터센터가 지진과 같은 천재지변으로 소실된다면 한번에 모든 것을 잃을 수도 있다. 적어도 자기 장비에 자기가 데이터를 가지고 있으면 그 데이터의 운명은 자신의 운명과 동일하지만, 클라우드에 아웃소싱하는 순간 자신의 운명과는 상관 없어진다는 점에서 사람들은 실패가 발생하면 더 쉽게 멘탈 붕괴에 빠질 것이다. 게다가 데이터센터는 매우 많은 사람과 서비스를 담고 있기 때문에 단 하나의 실패가 매우 광범위하게 영향을 끼치는 "single-point-of-failure" 역할을 하게 될 공산이 크다.
IT의 흐름에서 자기완결성·중앙집중식 vs. 분산화·전문화·조합성의 구도는 아마 앞으로도 계속 반복되지 않을까 싶다. 어느 것이 좋다 나쁘다기보다는 각기 장단점이 있는데, 하드웨어의 성능과 시장의 성숙도(기술적인 장벽을 뛰어넘을 수 있는 사용자의 비율 차이)에 따라 그 선택이 달라질 것이다. 앞으로 15년 후에는 어떻게 변해있을까?
이번 주 릴리즈 예정인 Python 3.4의 주요 변화사항으로 asyncio 라이브러리가 추가된 점을 꼽을 수 있다. 개인적으로는 unicode 대통합 이후 가장 반기는 변화라서 따로 글로 남겨본다. 우선 asyncio 라이브러리가 비동기 처리를 구현하는 핵심 구성요소인 coroutine 개념에 대해 썰을 좀 풀어보겠다.
프로그래밍을 할 때 동시에 2가지 이상의 작업을 처리하기 위해 사용하는 방법으로 대표적인 것이 multi-threading이다. process 또는 thread와 같이 운영체제 스케줄링의 기본 단위가 되는 실행 단위를 여러 개 만들어 각각이 서로 다른 작업을 처리하게 하는 것으로, 물리적으로 여러 개의 CPU 코어가 있는 경우 프로그래밍을 "잘"(lock을 가능하면 쓰지 않는다든지 shared data를 최소화한다든지) 하고 처리하고자 하는 연산이 입력데이터를 쪼개 처리할 수 있는 경우 높은 성능 향상을 볼 수 있다. 그러나 대부분의 프로그램은 single thread로 작성되므로 이처럼 입력 데이터를 쪼개 동일한 일을 하는 여러 개의 thread로 나눠주는 방식이 아니라면 큰 성능 향상을 보기 어렵고 데이터를 어떻게 쪼개고 어떻게 나눠주는지에 관한 구조를 모두 신경써야 하므로 프로그래밍도 복잡해지는 문제가 있다.
그 다음으로 많이 볼 수 있는 동시성 구현 방법은 event-driven programming이다. 구현 방법에 따라서는 멀티코어 CPU를 활용하도록 만들 수도 있지만 기본적인 컨셉은 하나의 thread 안에서 여러 개의 작업을 어떻게 잘 나누어 scheduling할 것인가에 초점을 맞춘다. Event-driven programming은 말 그대로 작업 별로 입력 이벤트가 발생하였을 때( = 연산할 꺼리가 생겼을 때) thread를 깨워서 그 작업을 처리하게 만드는 것이다. 따라서 이벤트를 여러 개 등록하고 각 이벤트를 모니터링하는 메커니즘이 필요한데, 최근의 운영체제에서는 epoll (Linux), kqueue (BSD), IOCP (Windows)와 같은 API들을 제공하고 있어 user process가 하기 어려운 blocking 작업과 IO event 모니터링을 효율적으로 구현할 수 있게 도와준다.
이와 달리, Coroutine은 동시성에 대한 접근 방법이 좀더 특이하다. 여기서는 일반적으로 우리가 함수(function 혹은 method)라고 부르는, 프로그램의 가장 작은 실행단위(routine)를 쪼개어 여러 각 subroutine들이 '번갈아' 실행되도록 한다. 쪼개는 지점은 프로그래머가 직접 정해주는데, 그렇게 만들어진 여러 개의 각 진입점을 그때그때 돌아가면서 혹은 특정 이벤트가 발생했을 때 coroutine scheduler가 원하는 순서대로 호출한다. 비유적으로 표현하면, 기존의 multi-threading이나 event-driven programming은 언제 "깨어날 지"를 운영체제나 라이브러리가 결정해주는 데 반해 coroutine에서는 언제 "잠들 지"를 프로그래머 스스로 결정하는 구조이다. "Cooperative routines"라는 이름에서 알 수 있듯이 스스로 제어를 양보(yield)하고, 이때 coroutine scheduler는 바로 다음 시점에 block하고 시스템의 이벤트를 기다릴 것인지 아니면 다른 coroutine을 실행할 것인지 선택한다.
Event-driven programming은 CPU 자원을 필요할 때만 쓴다는 점에서 효율적이지만 프로그래머의 관점에서는 헬게이트에 가깝다. 그 이유는 개별 이벤트가 독립적으로 처리된다는 가정을 바탕으로 하기 때문에, 여러 개의 이벤트가 하나의 일련 작업으로 이어져야 하는 경우 내가 "몇 번째 단계"에 있는지(state) 프로그래머가 스스로 tracking해야 하기 때문이다. 대부분의 프로그래머는 socket programming을 배울 때 "순서대로" socket을 열고 connect하고 recv/send를 번갈아 호출하고 할일이 끝나면 close하는 방식의 사고에 익숙할 것이고, 저 과정을 매번 다른 이벤트로 처리하고 특정 순서에 잘못된 이벤트가 오지는 않을까 노심초사해야 한다면 벌써부터 머리가 복잡해질 것이다. 이때 빛을 발휘하는 것이 바로 coroutine이다. 프로그래머는 그냥 원래 익숙한 순서대로 routine을 짜되, blocking call이 발생하는 부분마다 yield하도록 표시를 해두면 coroutine scheduler가 각 yield 후 알아서 connect가 완료되었을 때, recv/send가 완료되었을 때, close가 완료되었을 때 coroutine을 이어서 진행해 줄 수 있는 것이다. 이러한 coroutine이 여러 개 있다면? 각각을 그때그때 이어서 실행하면 되니까 자연스럽게 동시성 구현이 가능하다. 하지만 coroutine 방식에서는 "비협조적인" 코드를 강제로 context switch시키지 않으므로 모든 코드가 coroutine을 염두에 두고 작성되어야 한다는 주의사항이 있다.
그렇다면 coroutine을 실제로 프로그래밍에 사용하려면 무엇이 필요할까? 첫번째는 함수를 중간에 "멈출 수 있는" 프로그래밍 언어의 문법적 지원이 필요하고, 두번째로는 기존의 blocking call들이 coroutine scheduler에게 완료 통지를 해줄 수 있어야 한다. 첫번째 조건의 사례로는 Python에서는 generator delegation이라고도 불리우는 yield from 명령어를 통해 가능하며 C#에서는 await 키워드가 같은 역할을 한다. Java나 C++처럼 언어적인 지원이 없는 경우 future 패턴과 callback을 통해 비슷한 구현이 가능하지만 coroutine에서 block하는 지점이 많아질수록 중첩된 callback을 많이 만들어야 하므로 코드를 깔끔하게 유지하기 어렵다. 두번째 조건을 만족시키려면 기존의 socket, threading, queue 등의 blocking call을 제공하는 라이브러리가 모두 통째로 coroutine을 지원하도록 바뀌어야 한다! Python에서는 그래서 gevent와 같은 3rd party library들이 표준 라이브러리를 런타임에 구현체를 바꿔치기하는 monkey-patch 방식을 이용해서 구현된 경우가 많았다.
그런데, Python 3.4에서는 드디어 이러한 coroutine 지원 라이브러리가 표준 라이브러리에 포함된 것이다. asyncio라는 이름으로 말이다. 최초 API는 Python 창시자 Guido van Rossum이 2012년 12월 PEP-3156을 통해 제안했고 reference implementation으로 Tulip 프로젝트를 진행하다가 이제 완성도가 충분하다고 판단하였는지 표준 라이브러리에 그대로 집어넣었다. 기존에 tulip으로 작성된 코드가 있다면 "tulip" 패키지 이름을 "asyncio"로 치환하기만 해도 코드가 동작할 것이다. 특히 Python 3.3에서 추가된 yield from 구문을 이용하면 C#의 await 키워드와 거의 똑같은 느낌으로 함수 호출을 비동기적으로 한다고 편리하게 명시할 수 있다. 예를 들면 time.sleep(1)은 yield from asyncio.sleep(1)로 바뀌는 식이다.
나름 Python 얼리어답터라고 자부하는 내가 이걸 보고 그냥 지나칠 수가 없었다. 그래서 하루 동안 삽질해서 나온 결과물이 asyncio 기반의 Minecraft-IRC 중계 봇! 원래 구현은 bug-prone한 단일 루프로 구성되어 있었는데 이걸 완전히 갈아엎어서 IRC 통신, Minecraft 통신, tick 타이머 요렇게 3개의 루프로 나누고 각 루프를 coroutine으로 만들었더니 마치 single thread 프로그래밍하는 것처럼 직관적인 코드를 유지하면서도 동시성을 보장하는 아름다운 코드가 되었다. Python의 asyncio 패키지는 나중에 stdout과 network/cpu를 동시 모니터링하는 실험스크립트 작성에도 유용하게 쓰일 것이다.
아무튼 이렇게 Python 3로 넘어올 이유가 하나 더 생겼다. 다들 넘어오시라. ㅋㅋㅋㅋㅋㅋ (사실 Python 2.x용으로 Tulip을 backport한 Trollius 프로젝트가 있기는 하다... -_-)
※ update 3/10: 일부 문장 흐름 및 내용 연결 자연스럽게 함.
이번 주 월화수 3일간 포르투갈의 카스카이스(Cascais, Portugal) 열리는 ACM SOSP (Symposium on Operating Systems Principles) 학회에 다녀왔다. 비행기표 끊을 때 프랑크푸르트에서 환승하고 리스본으로 가는 비행기편이 아주 밤늦게 도착하는 것밖에 없어서 시차 적응 때문에 학회 당일 피로하지 않도록 하루 일찍 가는 편을 택했는데, 덕분에 포르투갈의 관광명소인 Sintra를 돌아볼 기회가 있었다. (온통 비바람 때문에 고생하긴 했지만... ㅠㅠ) 어쨌든, 관광에 대한 건 플리커 사진세트에 붙어있는 설명을 참고하고, 이 글에서는 학회 내용에 대한 것을 정리해볼 것이다.
플리커에 올려둔 사진 모음.
내가 작년 이맘때쯤 갔던 OSDI에 대해 들어본 사람이라면 아마도 SOSP도 알 것이다. 이 두 학회는 각각 USENIX와 ACM이라는 두 단체가 거의 같은 내용을 가지고 격년제로 번갈아 여는데, 실제로 참여하는 학생들이나 연구자 커뮤니티는 똑같다. 역사는 SOSP가 훨씬 오래되었는데, 1967년부터 시작했으니까 시분할 시스템이라는 개념이 막 탄생하던 때쯤부터 이어져온 시스템 분야 최고의 학회이다.
이번에 내가 학회에 간 목적은 크게 1) 포스터(extended abstract, 사실 실제 발표한 포스터는 설명 흐름을 부드럽게 하려고 순서가 살짝 바뀐 부분이 있음) 발표와 socializing을 통해 PacketShader 후속 연구와 관련한 피드백을 받고 PTask 및 Click modular router의 저자와 직접 만나 홍보 및 의견 나누기 2) 내년 인턴십 자리를 위해 기업들 미리 찔러보기 요렇게 두 가지였다.
포스터 발표에 대한 반응은 작년과 비슷했는데, PacketShader를 알고 온 사람들은 차이점이 무엇인지 무슨 추가적인 work을 하려는 것인지 물었고, 모르고 온 사람들은 GPU의 자체의 특징에 대해서 물어보는 경우가 많았다. 어떤 사람은 "experimental platform"이라는 말에 꽂혔다면서(?) 자기가 Emulab testbed 참여하는데 어떻게 쓰일 수 있는 거냐 묻기도 했다. 새로운 아이디어에 대한 피드백은 딱히 없었다. 몇 가지 이렇게 해보면 어떻겠냐 라는 제안은 받았는데 우리가 연구 과정에서 생각해본 범위 내였다. 예를 들면 branching/diverse code path에 약한 GPU에서 하기 어려운 router pipeline을 통째 GPU에서 구현하면 어떨까 라든지, 현재는 proprietary driver로 인해 불가능한 NIC-to-GPU direct copy라든지.
그래도 PTask 저자였던 Christopher Rossbach와의 만남이나 Click modular router 만든 (지금은 하버드 교수인) Eddie Kohler와의 만남은 그 사람들의 생각이 어떤지 알 수 있어서 소기의 성과를 건질 수 있었다.
PTask는 GPU에 대한 추상화를 운영체제에서 직접 제공해야만 운영체제 스케줄링에서 GPU의 workload나 CPU interaction을 함께 고려할 수 있어 더 나은 성능과 performance artifact를 줄일 수 있다는 것이 핵심이고, 여기에 disjoint memory를 사용하는 GPU로 오가는 dataflow를 datablock이라는 덩어리와 port끼리 연결관계를 미리 정의해놓는 일종의 UNIX pipe 개념을 활용해 다단계 행렬 곱셈 등에서 발생하기 쉬운 중복 복사를 막겠다는 아이디어가 들어가있다.
내가 발표 끝나고 했던 질문1은 datablock의 내용 변경 여부에 따른 GPU/CPU side의 invalidation 과정에서 datablock 통째로 하는 것이 좋을지 아니면 좀더 finer granularity (예를 들면 PacketShader에서는 한 datablock에 여러 개의 packet이 들어있을 수 있으니까)로 하는 것이 좋을지 물었는데, PCIe bus 타는 횟수를 줄이려면 자기가 한 것처럼 통째로 하는 게 좋지 않을까 라는 답을 들었다. 나중에 쉬는시간에 만나서 현재 Windows용 버전밖에 없는 것 같은데 공개할 계획이 있는지 물어보니 지금 코드는 MSR 내부 사정으로 공개가 불가능하나 참여한 대학원생들이 Linux 버전을 만들고 있다고 하고, PacketShader 팀하고 같이 일해보고 싶다고도 했다. 나중에 다른 사람들 얘기로는 PTask 연구의 문제점을 짚는다면 실제로 그러한 abstraction이 유용한 경우가 얼마나 있을 것인지 설득력이 다소 부족했다는 것을 들 수 있는데, PacketShader가 만약 PTask의 아이디어를 써서 큰 이득을 볼 수 있다면 대표 사례가 될 수 있기 때문이 아닐까 싶다.
Eddie Kohler를 만난 이유는, 내가 요 근래 Click + PacketShader-style HW optimization을 테스트해보면서 Click이 몇 가지 근본적인 한계가 있다는 것을 알게 되었기 때문이다. 그 한계란 약간의 코드 수정으로 NUMA-aware thread affinitization이나 IRQ pinning을 Click에 적용할 수는 있으나 싱글코어 시절 만들어져 나중에 멀티코어로 확장된 녀석이다보니 공통 데이터(router graph 등)에서 NUMA node crossing이 발생한다거나 user-level packet I/O가 특정 코어에서 병목이 된다거나(이건 pcap의 문제일 수도 있음) 하는 것들이다. 그래서 내가 물어본 것은 Click의 다음 step이 뭐라고 생각하는지였다. 그랬더니 대답 대신 질문이 되돌아왔는데, high-performace에 집중할 것인지 modularity + reasonable performance를 만들 것인지 아니면 정말 사람들이 쓰고 싶은 걸 만들 건지 알아야 한다는 것이었다. 어떻게 보면 모두 목표이긴 한데, 내 생각은 modularity는 적정한 수준까지만 쪼개고 performance에 집중하는 쪽이다. 아무튼 그러면서 덧붙이는 말이 자기는 Click의 performance를 위해 개발해온 게 아니라 correctness 쪽으로 집중해서 개발해왔다는 것. 결국 performance에 집중하려면 Click을 뜯어고치는 것보다는 새로운 코드를 짜는 게 낫다는 이야기였다.
어쨌든 직접 만나 이야기하니 재밌었다. 논문으로만 보던 사람들이 실제로는 어떤 사람인가 보는 것도 재밌고, 메일 주고받거나 하는 것보다 직접 눈앞에 두고 대화하는 것이 얼마나 더 효율적인지는 정말 안 해보면 모를 것이다.
다만 역시나 대화에 '적절하게' 끼어드는 것이 가장 어려운 일이었다. 이쪽 학회에 오는 서양 친구들은 기본적으로 '아무때나 끼어들어서 말 걸어도 괜찮아요' 모드인데 무언가 남의 말(그것도 교수님들 같은 윗사람들의)을 끊는 것이 실례라는 느낌을 항상 가지고 있는 동양 쪽 학생들로서는 언제 하고싶은 말을 어떻게 꺼내야 하는지 그 감이 잘 없다. 이럴 땐 두 가지 방법이 있는데, 에라 모르겠다 하고 끼어드는 방법이 있고 아니면 적당히 눈치를 줘가며(?) '이 친구가 뭐 말할게 있는 것 같은데' 하면서 알아서 끊어주기를 기다리는 방법이 있다. 문제는 인기있는 사람일수록, 말발이 좋은 사람일수록 전자가 어렵다는 것.
인턴십 관련해서는 아직 확정된 건 아무것도 없지만(내년에 울 교수님이 안식년 가시면 랩사람들을 대부분 인턴으로 내보내실 거라는 정도?) 일단 Facebook과 Google 쪽을 찔러봤고, 나중에 PTask 저자인 Rossbach나 다른 인맥을 통해 MSR도 찔러보려고 생각 중이다. 이런 학회에는 대개 스폰서 기업들의 비공식 recruiter들이 돌아다니기 때문에 나중에 실제 지원할지 어떨지는 몰라도 일단 눈도장이라도 찍어두는 셈이다. 내년에 "new" PacketShader가 어느 정도까지 논문이 될지 모르겠지만, 박사과정에서 인턴십을 간다면 기본적으로 논문을 쓸 수 있는 주제와 환경으로 가는 것을 교수님들이 선호하기 때문에 아마 그 연장선상의 일을 하는 쪽이 되거나, 그걸 응용·적용할 수 있는 약간 다른 토픽을 하는 쪽이 될 것이다.
논문 발표 중에서는 역시 내 논문과 가장 관련있는 PTask가 제일 기대되었지만 막상 발표는 그냥 그런 느낌이었고, 발표 스킬 자체만으로 본다면 MSR의 Jame Mickens라는 사람이 최고였다. Atlantis라는 Javascript/CSS/HTML parsing/rendering engine에 exokernel 개념을 도입한 웹브라우저에 대한 발표였는데, 문제 자체는 웹개발 좀 해본 사람이라면 누구나 아는 식상한 것이지만 그걸 너무나 재미있고 박력있게 풀어가서 그대로 몰입이 되었다. 발표들의 타입도 여러가지가 있었는데, Prezi를 이용해 화려하게 진행한 것부터 시작해서(개인적으로는 좀 산만하다는 느낌) 기술적인 디테일을 아주 상세히 다루거나 혹은 그 반대로 motivation과 evaluation만 보여주고 기술적인 내용을 질의응답으로 커버해버리는 경우까지 다양했다. Deterministic threading 발표가 많아 이게 화두인가 했는데, MIT 다니는 태수형 말로는 사실 강력한 motivation이나 usecase는 별로 없는데 일단 커뮤니티에서 어떻게 되는지 지켜보자는 느낌으로 근 몇년간 이쪽 논문들을 많이 뽑아서 보여주는 것 같단다. 기타 아이디어나 구현 방법이 모두 괜찮다고 생각되는 건 CryptDB 정도였고, 데이터분석을 통한 통찰로는 그와 함께 best paper 상을 받은 "File is not file" 정도가 있었다.
어쨌든 이 학회 통해서 느낀 건, 내가 누군가를 만나서 무슨 이야기를 해야겠다 하는 목적이 분명한 상태로 가면 훨씬 더 재미있게 사람들과 대화할 수 있다는 것이다. 비록 나와 정확히 같은 분야는 아니지만 그쪽의 아이디어를 내 연구에 어떻게 적용해보면 좋을 것 같다라든지, 혹은 근본적으로는 같은 문제를 어떻게 다르게 접근하는가 살펴보는 것이 직접적으로 연구와 관련되기 때문일 것이다. 얼른 1저자로 제대로 발표도 해보고 싶다.
이런 학회에서는 보통 발표 끝나면 중간중간 설치되어 있는 마이크에 쪼르르 달려가 줄서서 한사람씩 질의응답 주고받는 식인데, 청중들의 수준이 대단히 높기 때문에 질문 하는 것 자체도 상당히 긴장되는 일이다. ↩
요즘 연구실에서 워크샵 논문을 하나 준비하고 있다. 얼핏 보면 그리 어렵지 않은 듯하면서도, 막상 실제로 구현하려면 꽤 생각해야 할 것이 있어서 생각보다 어려움을 겪고 있다. 이미 있는 코드 분량이 꽤 되고 리눅스 커널 드라이버도 함께 맞물려 돌아가는 프로그램인데다 성능도 민감하기 때문에 생각보다 고려해야 할 것이 많은 것이다.
문제는 추상화다. 나도 '추상화의 덫'에 걸리지 않도록 조심해야 한다는 사실 정도는 알고 있지만, '나중에 유지보수할 일'을 생각해서 코드를 짤 때 되도록이면 기본적인 추상화는 하려고 하는 편이다. 하지만 프로그래밍에 데드라인이 생기면서부터는 이것이 만만치 않은 일이 된다. 추상화는 잘 할수록 나중에 좋지만, 데드라인이 있는 일에서는 결국 어느 정도 수준까지만 하고 포기해야 하는데, 가끔 이럴 때 장인정신(...)이 발휘되면 곤란한 상황에 처한다.
이쪽 시스템 분야로 내공을 쌓으신 연구실 선배와 이야기하다보면 많이 느끼는 차이점이 있다. 프로그램의 어떤 부분에서 임의의 16-bit integer key로 table lookup을 해야 하는데 나는 이것을 hash table로 짜야 되나, 그럼 이걸 어떻게 간단하게(적은 노력으로) 짤 수 있을까, 라이브러리를 쓴다면 뭘 쓰는 게 좋을까, C++ 인터페이스를 쓰는 게 좋을까 그냥 C로 하는 게 좋을까, random dereference를 하면 그 자체가 lookup 오버헤드가 되지는 않을까 등등등을 꼬리에 꼬리를 물고 고민하는데, 선배들과 이야기해보니 간단하게 그 table에 들어가는 item 개수가 많아야 수백개 정도일 것이므로 그냥 array에 때려박고 index로 접근하게 한 다음 table 변경될 때도 일부만 잘 고치려 할 필요 없이 전체 다 재생성하도록 해보고 나중에 성능 보고 더 나은 방법을 쓸지 말지 결정하자는 결론이 나왔다.
그러니까 요는 처음부터 너무 미래의 걱정을 하지 말라는 이야기다. 일단 지금 필요한 수준에 맞게만 구현하고 문제가 있으면 그때 가서 고치자는 것. 이 이야기를 건축에 비교해볼 수 있다. 물리학이나 공학이 지금처럼 발전하기 전에는 (상징성이나 예술성이 목적인 경우를 제외하면) 같은 기능적 목표를 충족시키기 위해 지금보다 훨씬 많은 재료가 들어갔으나 기술이 발전할수록 점점 그것이 최소한 필요한 만큼만 쓰게 되는데---사실 건축뿐만 아니라 많은 분야가 그렇다---처음부터 프로그램을 모든 경우를 대비해서 비대하게 짤 필요 없이 필요한 만큼씩만 덧붙여나가는 것이 이와 비슷하다.
그나마 '얼핏 보기에 간단한' 정도의 일도 이런 고민을 하게 만드는데, '얼핏 보기에도 어려운' 정도의 일을 하려면 아직도 내공을 더 많이 쌓아야 할 것 같다. 프로그래밍이라는 게 항상 끊임없는 의사결정의 과정인지라 개발자 자신이 처한 사회적 맥락, 프로그램 코드가 속해있는 기술적 맥락 모두를 잘 꿰뚫어보지 않으면 여러 의미로 좋은 코드가 나오기가 정말 어렵다.
(살짝 덧붙이자면, 그래도 ipv4와 ipv6를 하나의 인터페이스로 통합하려고 했던 시도는 그나마 빨리 접어서(...) 다행이다. -0-)
앞서 공지한 바와 같이, 10월 1일이부터 8일까지 5박 7일 일정으로 첫 해외 학회 출장을 다녀왔다. 다녀온 학회의 공식 명칭은 9th USENIX Symposium on Operating Systems Design and Implementation (일명 OSDI)이며 10월 4일부터 6일까지 캐나다 밴쿠버에서 열렸다. 컴퓨터 시스템 분야에서는 가장 인정받는 최고의 학회라고 할 수 있겠다. 이번 출장을 통해 아메리카 땅을 처음 밟아볼 수 있었고, 전산의 기원지이자 중심지인 미국의 파워도 실감할 수 있었다. 또 미국 유학 중이신 여러 선배들을 만날 수 있는 좋은 기회이기도 했다.



본격 논문 프레젠테이션이 이뤄지는 technical session은 3일 동안 진행되었으나, 나는 그보다 이틀 앞서 "Diversities in Systems Research"라는 작은 워크샵에 참석하였다. 학문적인 내용이 아니라 '대학원 생활 잘 하는 방법'을 공유하는 워크샵이었는데, 석사 1년차로서 듣기에는 더할나위 없이 좋은 워크샵이었다. '논문은 언제나 떨어지라고 쓰는 것이니(...) 떨어졌다고 해서 펑펑 울고 개인적으로 실망하고 그러지 마라'라는 얘기부터 시작해서, 학회는 social networking이 가장 중요하다는 점도 알려주고, 대학원 공부하는 요령이나 academic job과 industry job의 차이점 등 유용한 내용이 많았다. (물론 미국 기준의 이야기이긴 하지만.) 교수님, 대학원생들, 인텔과 MS에서 온 사람 등등 30명 정도가 가족적인(?) 분위기로 모여서 진행되었고, 특히 나처럼 해외 학회에 처음 가보는 것이라 아는 사람이 아무도 없고 그런 입장에서는 사람들과 친해지고 본격 tech session에서 말 걸 수 있는 사람들을 미리 만들 수 있는 좋은 기회였다. 여기에서 학문적 관점의 문제를 푸는 것도 재미있지만 스타트업에서 일해본 경험으로는 학문적이진 않지만 현실에서는 중요한 여러 문제들이 있고 그걸 푸는 것도 재밌다는 것을 알기 때문에 나는 박사과정을 계속 하는 것이 좋을지 고민된다는 질문을 하였더니, 내가 만든 무언가를 실제로 사람들이 사용하는 것이 가장 보람되다면 industry로, 새로운 아이디어를 제안하고 사람들과 공유하는 것 자체가 즐겁다면 academy로 가라고 명확하게 대답해주더라. (근데 난 둘 다 재밌을 것 같다는 것이...orz) 혹시 둘 다 하고 싶다면 일단 Ph.D를 먼저 따고 나중에 industry로 가는 것이 좋다는 것과, research intern을 반드시 해보라는 조언도 받았다. 참고로, 미국 대학원은 우리나라처럼 석사/박사가 명확하게 분리되기보다는 (학교마다 차이는 있지만) 박사과정을 하면서 중간에 석사 수료를 받을 수 있는 식이었다. 스웨덴 교환학생 때 보면 유럽은 학사+석사를 합쳐 5년에 끝나는 체제였던 것과는 또 다르더라. 또, 연구 동향 세션에서는 MSR/Google/Yahoo 등에서 나오는 논문들처럼 연구용이나 수업용으로 대용량 클러스터를 써보고 싶은데 현실적으로 어렵더라 이런 얘기를 했더니 인텔에서 온 사람이 Amazon이랑 긴밀하게 일하고 있다며 가상화 클러스터의 artifact 문제를 해결하고 더 많은 research community를 끌어들이기 위해 노력하고 있다는 얘기도 해주었다.
이렇게 이틀을 보낸 다음날 본격 학회 일정이 시작되었다. 몇 가지 기억에 남는 발표들만 얘기해보겠다. 위의 워크샵에서 했던 미니 포스터 세션에서 FlexSC라는 걸 들고나와서 몇 가지 질문을 했었는데, 알고보니 그게 첫번째 세션 발표였고 그 사람이 1저자였다; Linux systemcall에서 exception을 이용하지 않고 multithread로 만들겠다는 아이디어였는데, 나중에 사람들과 얘기해보니 다들 비슷한 생각을 하고 있었던 모양이나 이 팀이 시기적절하게 좋은 결과를 낸 것 같다. Linux many core scalability 발표는 나중에 전해들은 이야기인데 원래 linux는 scalable하지 않다는 걸 보이려고 하다가 조금(커널코드 5천줄 정도?) 고쳐보니 생각보다 결과가 잘 나와서 방향을 반대로 바꾼 거라고 한다. 살짝 기대했던 Facebook의 Haystack 발표는 그냥 잘 엔지니어링했다는 것 말고 뭔가 새로운 아이디어가 있거나 한 게 아니라서 실망이었다. 주변에서 태수형의 1저자 발표로 많이 기대했던 selective re-execution은 태수형이 아직 1년차라는 이유로(?) 교수님이 대신 발표를 맡아버려서 아쉽게도 태수형의 발표를 볼 순 없었다. 시스템 침입/침해 사고에 대응하는 방법으로 re-execution이라는 게 있다는 것 자체를 처음 본 것이라 신기했는데 기존 방법은 매우 많은 리소스를 요구하지만 action history graph를 잘 분석해서 적은 리소스로 복구 가능하게 했다는 내용이었다. 대체로, 시스템 분야 발표들을 보니 컴퓨터 성능이 충분히 좋아지니까 기존에 못하던 것들을 약간(수 퍼센트 정도)의 오버헤드를 감수하고라도 더 고차원적이고 새로운 요구를 해결하는 아이디어를 추가하는 느낌, 아니면 기존 구조를 멀티코어 시대에 맞게 고치는 느낌이었다.
또다른 큰 축으로 determinism을 운영체제 수준에서 보장해주겠다는 것이 있었다. 기존 multithreading 모델 자체가 프로그래밍 실수가 잦다(뭐 이쪽 분야에선 수도 없이 나온 이야기이긴 하다)는 점 때문인데, 이들 역시 deterministic하게 만듦으로 인해 발생하는 오버헤드를 어떻게 잘 줄이느냐가 관건인 듯했다. 특히 deterministic execution 보장뿐만 아니라 record & replay를 가능하게 해서 디버깅을 쉽게 한다는 점은 맘에 들었다. (오에스 pintos 플젝할 때 1000번 돌리면 한번 뻑나고 뭐 이런 버그 잡으려면 꼭 필요한 기능이다. ㅋㅋㅋ) 시스템 설정을 자동화하거나 설정 오류를 잘 잡아주겠다는 연구들도 있었는데, 그닥 잘 될 것 같지 않아서 큰 흥미는 없었지만(...) 그만큼 대규모 시스템에서 사람에 의한 설정 실수가 큰 문제가 되고 있고 research interest로 받아들여지고 있다는 것을 알 수 있었다. 얼마 전 Facebook에서도 설정값 잘못된 것을 자동으로 고치려는 내부 시스템들의 오작동이 일파만파 퍼지면서 전체 시스템을 다운시킨 사례가 있었으니 뭐.
데이터센터 쪽 연구들로는 computation과 data를 어떤 캡슐화된 단위로 보고서 클러스터 내에서 어떻게 잘 재배치·재활용할 것인가 하는 것들이었다. 특히 기존의 MapReduce 모델이 가지는 한계를 해결하고자 한 시도들이 몇 개 있었는데, 많은 사람들의 관심을 받은 Google의 Percolator도 그런 것 중 하나였다. 지난 4월부터 구글 검색 인덱스 백엔드에서 MapReduce를 버리고 Percolator로 바꿨다고 하는데, 구체적으로 PageRank를 이걸로 어떻게 구현했는지는 소개되지 않았지만 BigTable에 distributed transaction을 도입해 수십분 단위의 인덱스 갱신 시간을 문서 단위로 매우 빠르게 업데이트할 수 있도록 바꿨다는 것이 골자였다. 아마 트위터 실시간 검색 같은 것도 이걸로 구현한 것일 테다. 그리고 "Active" key-value storage를 구현한 Comet 발표도 재미있었다. memcached를 비롯한 많은 key-value storage는 그저 key/value pair만 왕창 저장할 뿐이지만, 여기에 "active" 개념을 도입해서 각각의 pair object가 이벤트 핸들러와 간단한 코드를 가질 수 있도록 하여 application-specific policy를 구현할 수 있도록 한 것이다. key-value storage의 문제점이라고 생각하고 있었던 부분인데 이렇게 접근하는 방법도 있구나 하고 배울 수 있었다. 마지막날 네트워크 시스템 분야의 rule-based forwarding 발표는 active의 의미를 조금 제한하여 원하는 만큼의 유연함은 확보하되 보안과 속도를 잡는 방법을 택했는데, 10년 전에 나왔지만 여전히 유효한 개념을 담은 논문에게 주는 상을 Active Network 논문이 받은 걸 보면 확실히 아직도, 그리고 앞으로도 계속 이쪽 연구들이 나올 것 같다.
가상화 쪽에서는 TaintDroid와 Turtles 프로젝트가 눈에 띄었다. TaintDroid는 안드로이드 플랫폼의 VM 자체를 고쳐 개별 변수, 파일 등을 모두 추적해서(이걸 얼마나 효율적으로 짰느냐가 강점) 개인의 위치 정보나 IMEI 등이 원하지 않는 시점에 외부로 전송되는 것을 탐지하고 사용자에게 이를 경고로 띄워준다. 앞에서 말한 것처럼 성능 희생을 조금 감수하고라도 고차원적 가치를 제공하기 위한 연구 흐름에 부합한다고 할 수 있겠다. Turtles 프로젝트는 이미 가상화 기능을 제공하는 OS(예: 윈도7의 XP Mode)를 어떻게 가상머신으로 돌리겠느냐 하는 nested virtualization 문제를 다룬 것인데, 아직 CPU 구조 상 지원되지는 않지만 몇가지 방법(multidimensional paging, single-level VMX multiplexing)을 통해 작은(6~8%) 오버헤드로 돌릴 수 있었다는 내용이었다. 그 외에 가상화 환경에서 clock timing을 어떻게 정밀하게 관리할 것이냐 하는 연구도 있었는데 나름 의미있는 작업이긴 하지만 큰 관심이 가지는 않았다.
아무튼, 이번 OSDI에서 발표된 전체 논문을 보려면 이곳을 방문하면 된다.
아침부터 저녁 늦게까지 계속 학회 일정이 이어진 데다 시차적응 문제까지 더해 아주 힘들었지만 승엽이형, 태수형, 민종이형, 상만이형, 박소연 박사님 등 미국 유학 중이신 여러 선배들 및 한국에서 오신 다른 분들도 만나고, 몇몇 발표자(FlexSC 발표한 Livio Soares, Rule-based Forwarding 발표한 Lucian Popa)와는 안면도 쌓을 수 있었다. 이를 테면 아침에 엘레베이터에서 만나 같이 걸어가면서 얘기했다든지 돌아올 때 공항에서 계속 마주쳤다든지. 하지만 여전히 미국 사람들의 빠른 영어와, 이미 서로 알고 있는 사람들의 대화에 끼어들기는 어려웠던지라 좀더 많은 사람들을 못 만난 것은 살짝 아쉽다.

포스터 걸어놓은 모습. 꼬박 한시간 반을 서있어야 했다;
포스터 세션의 경우 내가 포스터 발표를 한 덕에 저녁도 못 먹고(ㅠㅠ) 계속 사람들 와서 질문하는 거 대답해주느라 다른 사람들 포스터들을 거의 못 봐서 좀 아쉽기도 했지만, 내 포스터는 도이치텔레콤의 Rob Sherwood, 유타대학교 Robert Ricci, 인텔의 Mazier Manesa 등 몇몇 사람들이 관심있게 봐주었다. PacketShader가 여전히 임팩트있는 연구임을 확인할 수 있었고(메일로 논문 보내달라는 사람도 있었음), 가장 걱정했던 부분인 실제 라우터에서의 FIB update overhead에 대해 구체적으로 물어본 경우는 다행히(?) 없었다.1 피드백 중에 IPv4는 비교적 간단하게 구현 가능한데 OpenFlow에서는 패킷마다 routing table이 바뀌기 때문에 double buffering 적용이 어렵지 않겠냐는(lock overhead 등) 것이 있어서 이 부분은 내가 OpenFlow를 좀더 공부해봐야 할 것 같다. 포스터 세션 끝나고 정리할 때 한 사람이 안 가고 계속 설명 중이길래 가서 들어봤는데, Yagz Onat Yazr라는 친구가 클라우드 컴퓨팅의 리소스 배분 문제를 설명하고 있었다. 현실의 예를 들어가며 아주 흥분된 목소리로 재미나게(...) 설명해서 이해는 잘 되었는데, 이 친구 말이 논문도 그렇게(!) 쓰고 싶은데 잘 될지 모르겠다는 농담반 진담반(?) 이야길 해서 다들 웃었다. 아무튼 이 친구 설명은 다들 기술적인 내용을 다루고 있고 듣는 사람들도 그런 배경지식이 있는 사람들이라지만 설명 방법을 좀더 고민해볼 필요가 있겠다는 생각이 들게 해주었다. 포스터 세션 전체 발표 목록은 여기 있는데, "Monster poster session"으로 이름을 바꿨을 만큼 많이 뽑았더라.;
한편 한국인 선배들과 만나 이런저런 이야기도 듣고, BoF 세션의 community resource 톡이나 일상에서 내가 보고 느낀 것이나 유럽과의 분위기 비교 등을 통해 느낀 것은, 미국이 컴퓨터 시스템 분야는 단연코 원조이자 선진국이며 연구 규모도 크다는 것, 그리고 전체적으로 모든 것을 체계화·시스템화하려는 경향이 강하다는 것, 그러한 경향 때문에 대다수의 국민들은 조금 멍청(?)해도 잘 살아갈 수 있게 되어 있다는 것. 대신 사람과 사람의 끈끈한 정은 느끼기 힘들다는 것. 또, 우리는 미팅을 할 때 미리 다 논문도 읽고 그러는 것이 좋다고 생각하지만 미국 애들은 발표에 없고 논문에 있는 것이라도 일단 질문하고 본다는 것. 나는 tech session에서 보다가 궁금한 게 있으면 논문을 훑어봤는데 대개 내가 궁금해한 것 정도는 이미 논문에 다 있어서(...그러니 OSDI에 나왔겠지 ㅋㅋ) 질문을 못했는데, 미국 애들은 그런 거 신경 안 쓰고 일단 질문하고 보는 것 같았다. 선배들 말로는 이게 숙독하는 것과 비교해 나름의 일장일단이 있지만 어쨌든 짧은 시간에 효율적으로 공부하는 방법의 하나라면서, 미국 쪽에서 공부하려면 반드시 익숙해져야 하는 것이라고도 한다.
이번 출장 다녀오면서 역시 한국이 인터넷이랑 공항은 잘 되어 있구나 하는 느낌을 지울 수 없었다. 특히 미국 LA에서 환승할 때는 터미널마다, 항공사 카운터마다 시스템이 달라서 나처럼 좀 특이하게 미국 입국 후 다시 해외로 환승하는 경우는 미리 알지 않으면 헤매기 딱 좋게 되어 있었다. 인터넷으로 미리 '톰브래들리 터미널(인터내셔널 전용 터미널)에서 내리고 미국 입국 절차를 밟고 수하물을 찾은 후 터미널 2번으로 이동해야 캐나다행 비행기를 탈 수 있다'는 정보를 알고 갔기에 망정이지, 2번 터미널 찾는 것도 한참 헤맸고(결국 누군가한테 물어봐서 해결) 톰브래들리 터미널에서는 전광판도 시스템이 아예 달라 캐나다행 비행기가 나오지 않았기 때문에 아마 터미널을 바꿔 타야 한다는 걸 아예 모르고 갔으면 정말 비행기 놓쳤을 것이다.2 그래도 캐나다에서 돌아올 때는 밴쿠버 공항에서 미국 입국 절차를 다 밟고 LA에서 수하물 찾지 않고 체크인만 다시 하면 되었기 때문에 훨씬 편했지만 이때는 보안검색 줄이 엄청 길었다. 2번 터미널은 오래돼서 시설이 엄청 구렸는데 톰브래들리는 새로 지어서인지 상당히 좋은 편이었다. 공항 서비스면에서도 차이가 많이 났다. 인천공항과 밴쿠버공항은 무료 Wifi를 빵빵하게 쓸 수 있었는데, LA 공항은 유료 Wifi만 있고 (KT Wifi 로밍도 실패했는데, 앱에서 오프라인으로 제휴사 목록을 볼 수 있었음 좋겠다) 3G망도 엄청 신호가 약해서 배터리 소모가 심했다. 특히 보안검색할 때 우리나라에서는 신발 벗으면 잠깐이지만 임시로 신으라고 슬리퍼도 주고 바구니도 친절하게 다 가져다주는데 미국과 캐나다는 그런 거 얄짤 없더라.;; 그냥 다 알아서 해야 한다;
참고로 미국 입국은 이번이 처음 해보는 것이었는데, 열손가락 지문 다 찍고 안경과 모자 모두 벗고 얼굴 사진 찍고 하느라 조금 신경쓰이긴 했지만 다행히 무사 통과(?)하였다. 한번 해두니 두번째 캐나다에서 미국으로 갈 때는 오른손 네 손가락 지문과 사진만 다시 찍어서 확인하더라. 입국심사관이 뭐 하러 왔냐고 해서 academic conference 왔다고 하니 거기서 뭐 하느냐, 며칠 동안 있다 갈 거냐 이런 것을 물어봐서 잘 대답하니 별 문제 없었다.
아무튼, 이렇게 해서 첫 해외 학회 출장은 나름 잘 다녀온 것 같다. 출장 직전까지 할일이 잔뜩 있어서 쉬지도 못하고(인천공항에서 비행기 한 시간 지연된 덕분에 숙제 제출하고 막...아놔) 힘들었지만 사람들 만나는 건 언제나 즐거운 일인듯.
뭐 요즘이야 어디서나(?) 인터넷이 잘 되니 여전히 인터넷을 통한 연락은 닿겠지만 그래도 공지합니다.
내일 10월 1일부터 10월 8일까지 캐나다 벤쿠버로 OSDI 학회 출장갑니다. "Dynamic Forwarding Table Management in High-speed GPU-based Software Routers"라는 주제로 포스터 발표도 하나 할 예정입니다.
아이폰 데이터+와이파이 로밍을 써볼 기회가 생겼는데 과연 얼마나 잘 될런지 궁금하군요.
그럼 잘 다녀오겠습니다. :)
내가 그동안 했던 게임들을 꼽으라면 저 옛날의 커맨드앤컨커 시리즈(오리지날, 레드얼럿, 타이베리안선), 토탈어나이얼레이션(Total Annihilation), 스타크래프트가 있겠다. 아는 사람은 알겠지만 주로 실시간 전략 시뮬레이션(RTS) 장르를 즐겨왔고 실제로 본격적인 맵 제작은 거의 안 했지만 맵에디터가 있거나 혹은 내가 맵에디터를 만들 수 있는(!) 게임들을 주로 했다. RPG 류도 디아블로2 같은 건 조금 만져보긴 했었는데 노가다 뛰고 시간 투자가 많이 들어가는 것이 싫어서 거의 해보지 않았다.
그 중에서도 토탈어나이얼레이션은 중학생 때 유닛을 만들어보겠다고 전용 AI 스크립트 언어까지 공부하다가 실패한 기억이 있다. 그러나 내가 그런 열정을 보이는 것과는 상관 없이(?) 그만 이 게임 제작사인 Cavedog이 망해버려서(...) 프로듀서였던 크리스 테일러라는 사람이 나중에 Gas Powered Games로 옮겨가 슈프림커맨더(Supreme Commander)를 개발한다는 소식을 듣고 근 10년 동안 즐기던 토탈을 접고 무려 한정판 패키지를 지르기도 했다. 이후 관련 게임 커뮤니티를 개인 서버에 계속 호스팅해오고 있기도 하다.
다만 슈프림커맨더의 결정적 단점이라면 한 판을 플레이하는 시간이 매우 오래 걸린다는 점으로, 사람들과 2v2 이상 멀티를 하면 1시간에서 길어지는 경우 2~3시간까지 걸리기도 한다. 특히나 우리나라에서는 20~30분이면 한 판이 끝나는 스타크래프트에 익숙하고 사람들 성격도 급해서인지 매우 인기가 없었다. (첫번째 릴리즈는 국내 유통사를 통해 공식발매가 되었는데 별로 많이 안 팔렸는지 확장팩과 더 이후에 나온 슈프림커맨더2는 국내 발매조차 되지 않았다. 결국 구매대행을 이용하거나 STEAM을 이용해 달러 결제하고 온라인 구입해야 했다.)
하지만 슈프림커맨더 이후로는 대학 생활에 한창 바빠서(2007년 봄에 출시되었는데 이때가 가장 바쁜 시기중 하나였다.) 무려 클로즈베타부터 게임을 했음에도 불구하고 만년 늅(...) 상태로 남아있었고, 따라서 게임에 돈을 꽤나 쏟아부었으면서도1 큰 재미를 느끼지 못하고 있는 상황이었다. 게임 자체도 뭔가 다른 생산적인 활동에 밀려서 거의 하지 않았고 말이다.
...그러다가 최근에 주변 사람들의 소개로 시작한 게임이 바로 League of Legends(이하 LOL)이다.;;;
사람들이 "DOTA류의 게임" 또는 "DOTA 만든 사람들이 만든 게임"이라고 하는데 처음엔 무슨 말인지 몰랐다. 알고보니 워크래프트3에서 사람들이 "카오스"라는 유즈맵을 하는 걸 본 적이 몇 번 있는데(내가 있던 로봇 동아리 미스터에서 사람들끼리 동방에서 참 많이도 했었다. 나는 한번도 안 해봤지만.) 이게 그런 방식의 게임이라는 거다.
내가 해왔던 RTS들은 제한된 크기의 전장(맵) 안에서 지형지물을 이용하고 자원을 채취하여 건물과 유닛을 생산해 서로 싸우는 방식이었는데, DOTA에서부터 이어진 LOL은 제한된 크기의 전장을 이용한다는 점은 같으나 자원 채취와 생산이라는 개념이 없다. (굳이 말하자면 적을 죽일 때 버는 돈이 자원이랄 수는 있겠다) 다양한 시대적 배경을 가지는 RTS에 비해 판타지 세계관을 가지고 있다는 것도 특징이라면 특징으로, 플레이어들의 의지와 상관 없이 양측 진영에서 자동으로 생성되어 서로 싸우는 미니온들이라는 작은 병사들이 존재하고, 여기에 플레이어들은 각자 한 명의 영웅을 맡아 미니온들을 돕거나 상대편 영웅들과 싸우는 방식이다. 영웅들은 각종 스킬과 마법을 사용할 수 있고 게임 중 번 돈으로 아이템을 사서 능력치를 자기 입맛에 맞게 키울 수 있다.
한동안 말려서 하다가(...) 가만 돌아보며 재미 요소가 무엇일까 곰곰이 생각해보니 이렇다.
스타크래프트는 유닛 상성이 있어서 어느 정도 이를 이용한 조합적 플레이가 가능하지만, 토탈에 그나마 있었던 다양한 유닛의 특성이 슈프림커맨더에 와서는 무조건 물량전 위주로 바뀌는 바람에 뭔가 머리쓰는 재미보다는 빌드오더를 잘 맞추는 것이 중요해지고 빠른 컨트롤과 많은 플레이 경험이 필요해졌다. 그래서 게임에 많은 시간을 투자할 수 없었던 나로서는 뒤쳐질 수밖에 없었던 것이다.
그런데 LOL은 내가 매우 초보임에도 불구하고 거의 즉각적으로 흥미를 가질 수 있었다. 그 이유로 아이템과 특수능력을 조합하고 이를 적재적소에 사용하는 전략 구상을 매우 집중적으로 해야 하는 게임이기 때문에 다른 RTS 게임에서 느끼기 힘들었던 전략 설계의 intensiveness, 거기에 더하여 전략의 성공 여부를 매우 빠른 템포로 느낄 수 있다는 점을 들 수 있겠다. (LOL 커뮤니티에서는 '한타'라는 용어로 자기 편과 상대 편의 여러 영웅들이 함께 맞붙어 싸우는 상황을 표현하는데 이때 각 영웅별 특성을 잘 활용하는 것이 매우 중요하다. 서로 견제하거나 도망가는 게 아니라면, 10여초 만에 한타의 승패가 판가름난다.) 이것 또한 빠른 피드백이라는 점에서 flow의 또 다른 조건의 하나다.
사람들이 중독성이 높은 게임이라고 하는데, 이렇게 가만히 살펴보니까 다 그럴 만한 이유가 있구나 싶다. 대학원생인지라 게임할 시간이 그리 많은 건 아니지만, 이런 게임을 하면서 내부는 어떤 구조로 설계했을까 생각해보는 것도 재미있고(...아마 게임하면서 그런 거 생각하는 사람이 많진 않을 것 같지만 ㅋㅋ), 사람들에게 재미 요소를 주는 부분이 무엇인지 알기 위해 혹은 느끼기 위해 다양한 게임을 접해보는 것 자체는 좋다는 생각이 든다. 물론 전통적인 의미에서 스트레스를 풀기 위한 하나의 수단이기도 하고.
얼마 전에 이 게임 개발사(Riot Studio)가 별도의 유통사를 거치지 않고 직접 한국 서비스를 하겠다고 발표했다는데, 그러면 지금의 불안정한 접속 환경이 많이 나아지지 않을까 싶다. 오랜만에 재밌게 할 만한 게임을 하나 찾았으니, 이것도 가늘고(?) 길게(?) 즐겨봐야지.
참고로 나는 내가 메인으로 재미붙여서 했던 게임들은 모두 정품 구입하였다. 스타크래프트 오리지날, 브루드워, 토탈, 슈프림커맨더 및 확장팩/후속작, 워크래프트2, 커맨드앤컨커과 타이베리안선 모두. 레드얼럿과 심시티는 복사 방지 기술이 별로 없었던지라 친척한테 빌려서 했던 걸로 기억한다; 생각 외로 나는 게임이나 소프트웨어에 돈을 좀 쓰는 편인데--이런저런 소소한 프로그램들도 크랙을 구할 수 있더라도 일부러 정품 구입한 게 꽤 있다--내가 소프트웨어로 밥벌어 먹고 살아야 할 입장이라 정당한 대가를 지불하는 게 필요하다는 생각 때문이다. 나를 충분히 즐겁게 해준다면, 또 내 시간과 노력을 충분히 아껴준다면 그 자체로 가치를 지불하는 것이다. (다만 포토샵 같이 좀 너무 심하게 비싼 건...ㅠ_ㅠ 내가 필요한 기능만 선택해서 가격을 매길 순 없을런지... 나의 사용 패턴과 대체재의 존재 여부 등을 종합적으로 고려하여 내 사용 가치에 비해 가격이 너무 높은 경우는 때로 어둠의 경로를 이용하기도 하지만, 어둠의 경로는 대체재에 포함시키지 않는다.) 물론 그동안 그럴 수 있도록 경제적 여건이 허락해준 것도 있지만, 사실 조금만 관심을 가지면 크게 어려운 건 아니기도 한듯. ↩
구글이 텍스트큐브닷컴과 TNC를 인수했을 때만 해도, 나를 비롯해 TNF/Needlworks의 손길이 닿은 텍스트큐브가 구글 스케일로 아시아 시장을 타겟으로 하는 블로그 제작 도구로 보다 많은 사용자들에게 다시 재평가를 받을 수 있으리라는 어떤 기대가 컸었다. 초기에는 구글에서도 상당히 열정적으로 운영해서, 다른 구글 서비스들이 가지는 치명적 단점을 극복하고 고객 서비스도 비교적 잘 했었다.
하지만 구글은 매우 실망스러운 공지글과 함께 텍스트큐브닷컴을 블로거닷컴으로 통합한다고 한다.
블로거닷컴은 블로그 시장 아주 초창기부터 있었던 서비스로 이 또한 구글이 인수하여 운영하고 있는 블로그 서비스이다. 북미나 유럽 등지에서는 제법 사용되는 편이지만, 트랙백이나 카테고리 등이 편리하게 지원되지 않고 댓글 UI의 불편함이나 스킨 자유도가 떨어지는 등의 문제점을 비롯하여 단순히 기능적 번역만 되어 있을 뿐 서비스 운영 주체가 구글 본사기 때문에 한국어 같은 비유럽 언어권 고객 지원이 없는 것이나 마찬가지라는 점은 블로거닷컴이 한국 및 아시아 시장에서 지지리도 인기 없던 이유이다.
설치형 텍스트큐브의 경우 아무래도 소수 개발자들의 취향을 따라가는 면이 많다보니 UI나 사용자 경험 측면에서 그닥 좋지 못한 것이 사실이지만, 태터툴즈에서 출발해 다음으로 넘어간 가입형 블로그인 티스토리나 구글이 인수한 가입형 서비스인 텍스트큐브닷컴은 이를 아주 잘 정제하여 사용자들에게 상당히 좋은 반응을 얻었던 서비스들이다.
어쨌든 텍스트큐브닷컴이나 블로거닷컴 모두 구글이 운영하는 서비스들이고, 기업으로서 불필요한 비용 투자를 최소화해야 하기 때문에 사실 인수 때부터 구글이 사실상 중복되는 서비스인 이 둘을 그냥 공존하게 놔두지는 않을 것이라는 예상이 존재하기는 했었다. 하지만 텍스트큐브닷컴에서는 사용자들에게 구글이 텍스트큐브닷컴을 매우 중요시하고 있음을 강조해왔고 한동안은 서비스 업데이트도 충실히 진행하여 어느 정도 불안감을 잠재워놓았다. 이후 업데이트가 좀 뜸해졌으나 내가 전해듣기로는 구글에 인수된 서비스들이 모두 거쳐야 하는 악명높은(?) 플랫폼 통합 작업 중이라는 얘기를 들은 게 마지막이었다.
이익을 좇아야 할 의무가 있는 기업이고, 어쨌든 운영 권한은 구글이 가지고 있는 것이기에 그러한 통합 결정 자체를 내가 어떻게 반대할 수는 없다. (심적으로 반대하더라도 법적으로 어찌할 수는 없는 것이다.) 하지만 제대로 된 대책 없이 나중에 방법을 알려주겠다는 식의 불친절하고 일방적인 통보식 공지, 개발 인력 일부가 이미 블로거닷컴을 위해 일하고 있었다는 사실을 스스로 밝힘으로써 얻은 사용자들의 배신감, 악명 높은 구글의 고객 지원이 모두 합쳐져 구글코리아의 브랜드 가치가 크게 떨어지는 것은 안타까운 일이다. 그래도 구글코리아의 가장 좋은 서비스로 평가받고 있었는데 말이다.
개인적으로는 내 손길이 닿기도 했던 소프트웨어일뿐만 아니라 그 이름과 상표의 제작 과정에 참여했던 사람으로서 텍스트큐브닷컴을 통해 우리가 추구하고자 했던 블로그 도구의 어떤 한 이상향이 구글을 통해 언어의 장벽을 넘고 세계 시장에서 워드프레스, 무버블타입, 텍스타일, 블로거닷컴 등과 제대로 된 진검승부를 벌이는 모습을 보고 싶었는데 자본의 논리로 인해 그렇지 못함이 슬프고 안타까울 따름이다. 특히나 블로거닷컴은 기술적으로나1 사용 편의성 측면에서 텍스트큐브닷컴에 비해 매우 뒤떨어진다고 생각하기 때문에 블로거닷컴과 통합하게 될 경우 텍스트큐브가 메인이 되었으면 했지만 규모의 논리에 의해 그 반대가 된 것이 아쉽다.
오픈소스 설치형 블로그로는 세계 최고의 툴이 된 워드프레스도 태터툴즈가 시작할 당시를 생각해보면 기술적으로나 UI 면에서 대동소이한 상황이었다. 하지만 영어권이라는 막대한 시장과 언어의 이점을 안고 가면서 급속도로 성장했고, 풍부한 개발자 pool과 이미 잘 정착된 오픈소스 문화 덕분에 태터툴즈의 후신 텍스트큐브는 한국과 아시아 일부에서만 알려진 도구로 남은 사이 전 세계로 퍼져나간 것이다. 이는 실로 언어의 장벽이 문제라고밖에 할 수 없다. 이런 상황을 타개해줄 그나마의 희망이 구글이었는데...
설치형 텍스트큐브 개발팀의 경우도 지속적인 유지가 가능할지는 사실 불투명하다. 기존 멤버가 주로 계속 진행하고 있을 뿐 새로운 신규 개발자 유입이 거의 없기 때문이다. 안 그래도 본업 따로 있는 개발자들이 사용자 지원까지 해야 하는 상황이기 때문에 개발이 빠르게 진행될 수 없다. 이는 우리나라의 웹개발자 숫자가 아직 절대적으로 부족하고 시장 규모도 작아서 그런 것이라 생각되는데, 그냥 하던 멤버들이 계속 할 수 있다면 괜찮겠지만 10년 20년을 내다보면 역시 알 수 없는 일이다.
이러한 상황에서 이제 텍스트큐브라는 브랜드는 설치형 텍스트큐브만 가지게 되었으므로 그런 어려움들을 극복하고 이 이름에 대한 이미지를 쇄신하고 원래 목표했던 바를 이루어가는 것은 우리 TNF의 몫으로 남게 되었다.
이미 구글플랫폼 위에서 돌아가도록 모두 수정된지 오래일 테므로 대용량 서비스 측면에서는 기술적으로 더 우수할 수 있겠지만 프론트엔드 부분은 (텍스트큐브닷컴 개발자들이 참여했다는 템플릿디자이너 빼면) 확실히 텍스트큐브닷컴이 낫다. ↩
서버 이전 '거의' 완료하였습니다. IP가 바뀌었기 때문에 사용하시는 네임 서버에 따라 실제 접속까지 최대 2~3일 정도 더 소요될 수 있습니다. (이 글을 RSS 리더 서비스에서 먼저 발견하였으나 자신의 PC에서 접속이 안 되는 경우가 아마 이런 경우일 겁니다)
개인 서버이긴 하지만 딸려있는 사이트가 많아서 생각보다 신경쓸 게 많더군요;
몇 가지 삽질 로그:
cp 명령 이용할 때 symbolic link를 symbolic link로 놔두려면 -P 옵션 이용할 것. 이것 때문에 아파치 설정이 왜 안 바뀌나 몰라서 삽질. ㅠㅠtar 명령 이용해서 디렉토리 단위로 압축하고 풀 때, 푸는 명령을 내릴 때의 현재 디렉토리는 풀어진 디렉토리가 들어갈 상위 디렉토리로 하면 간단히 편하게 된다. 물론 -p 옵션으로 퍼미션 유지하는 거 빼먹지 말자.
...이 안 나오는 이유는 다름 아닌 현재 이 서버의 하드디스크가 사망할 조짐을 보이고 있기 때문이다. 물리적 서버에 대한 관리 부담을 줄이기 위해, 그리고 마침 집에 머무르는 기간이기 때문에 가상서버 호스팅으로 이전하고 물리적인 서버는 꺼내와서 다른 사람이나 동아리에 팔거나 기증하는 쪽을 생각하고 있다.
아무튼 그래서 서버 이전이 안정화될 때까지 몇몇 포스팅들은 다소 미루어질 수도 있음을 알려드립니다. (...)
2007년에 처음 출시되어 3G 버전 나오고 다시 3GS 버전이 나올 동안 우리나라에서는 그저 침흘리며 바라만봐야 했던 아이폰이 결국 우리나라에도 상륙했다. 첫번째 모델은 우리나라랑 통신 방식 자체가 달라서 그런가보다 했지만 3G는 이미 우리나라에도 거의 다 보급되어 있고 전세계적으로 쓰이고 있는 방식으로 정식 출시에 큰 기대가 모아져왔었다.
처음에 아이폰을 사기로 결정했던 것은 2008년. 그전까지 나에게 핸드폰이란 그저 전화와 문자만 잘 되면 되는 '통신기기'였을 뿐이다. 하지만 내가 개발한 프로그램을 핸드폰에 올리고 이를 전세계에 판매하여 수익을 낼 수 있다는 것은 애플의 폐쇄성에도 불구하고 대단히 매력적이었다. 핸드폰이 더이상 핸드폰이 아닌 범용 모바일 컴퓨터가 된 순간이다.
여기에 태극기가 박히기를 얼마나 오랫동안 기다려왔던가!
이후 나는 2004년형 모토로라 스타택을 가지고 버티고 버티며 기다렸고, 결국 그 폰이 아이폰 출시 3개월 전 액정이 맛이 가며 사망하자 형이 쓰던 중고 3G폰으로 기변하여 또 버티는 고생 끝에 아이폰을 개통하였다. 작년쯤인가 어머니께서 폰이 너무 낡았다며 하나 사주겠다고 하셨음에도 극구 만류하고 지금까지 기다려왔던 것이다.
중간에 가장 삽질했던 것은 2G -> 3G 기변은 번호이동처럼 처리되기 때문에 일명 메뚜기족을 방지하기 위해 만든 번호이동 90일 제한에 똑같이 걸린다는 사실을 전혀 몰랐다는 것이다. 내가 아이폰을 수령한 11월 30일이 정확히 90일째 되는 날이었기에 (다른 사람들은 예약배송지연에 개통 안 돼서 난리치는 와중에 행복하게도) 이날 개통문자를 받았지만 결국 개통에 실패하고(-_ㅠ) 이틀 뒤 유성온천역에 있는 직영대리점에 가서야 겨우 개통할 수 있었다.
하지만 KT가 진행한 예약판매는 문제가 많았다. 11월 22일 정오부터 예약판매를 시작하여 28일 토요일까지 배송해주겠다고 했는데 실제로 배송된 것은 빨라야 30일, 늦으면 12월을 넘긴 경우도 있었다. 게다가 받자마자 사용할 수 있는 것도 아니고 개통까지는 더욱 오랜 시간이 소요되어 심하면 배송받고도 일주일 넘게 개통되지 않은 경우도 있었다. 미리 잠정적으로 최대 수용 가능한 인원수를 정해놓고 거기까지만 예약을 받든지 해야 했는데, 6만명 넘게 받아버렸으니 늦어지는 건 이해되면서도 참 대책없이 진행했다 싶다.
나는 22일 오후 3시를 전후해서 예약하여 예약 대기자 순으로는 대략 2만명 대에 있었는데--그날 늦잠자서 그렇지 아마 정오부터 하는 거 미리 알았으면 예약페이지 오픈하자마자 했을 거다 ㅋㅋ--30일에 무사히 배송받고 그날 오후 개통문자와 안내전화까지 받았으니 가장 순조롭게 진행된 편이라 하겠다. (위에서 쓴 것처럼 번호이동 90일 제한 마지막날에 딱 걸리는 바람에 삽질을 좀 했지만.)
아이폰 스크린샷. 개통하기 전이라 '서비스 안됨'이라고 찍힌 걸 볼 수 있다.
어쨌든 나는 상당히 잘 처리된 경우인데, 예약구매자들에게 지급되는 쇼캐쉬 2만원이 또 문제였다. 쇼캐쉬는 폰스토어에서 현금처럼 쓸 수 있는 포인트인데, 예약구매자들에겐 전용 이벤트 페이지를 이용하여 시세보다 싸게 아이폰 악세서리를 살 수 있게 해주었다. 그래서 개통 후 정황을 살펴보다가 우선 보호필름을 붙이는 쪽으로 가보자 생각하여 인비지블쉴드 제품을 주문했는데 그게 무려 일주일 넘게 지난 어제 발송되어 다음 월요일에야 도착한다는 것이다. 곱게 쓴다고 조심조심하며 쓰고 있지만 이미 뒷면에는 잔기스가 조금 난 상태. 앞면은 강화유리라 아직까진 멀쩡하다. (케이스는 일단 보호필름만 붙이고 써보다가 상황 봐서 나중에 구입하든지 할 생각이다.) 이런 것도 주문하면 바로바로 확인해서 미리 물량 준비해놓고 해야 하는데 역시 일단 주문 받아놓고 뒤늦게 준비하는 듯해서 아쉽다.
첫번째로는 훌륭하게 인터넷을 사용할 수 있는 3G망이 이미 이렇게 잘 깔려있는데 왜 여태까지 이것을 그 비싼 데이터요금을 빌미로 못 쓰게 했는지 가장 이해할 수가 없었다. 속도는 대략 초창기 ADSL이라고 보면 될까. 다운로드는 상당히 빠르지만--신호 약한 Wi-Fi보다 빠름--업로드가 상당히 느리다.
내가 형이 쓰던 3G 중고폰으로 바꾸었을 때 한번 실험삼아(...) 위피용 미투포토를 다운받아 약 650KB 정도 되는 사진을 하나 올렸는데 SKT에서 데이터와 전혀 무관한 요금제에서 데이터요금이 4450원쯤 부과되었다. 이건 정말 말도 안 되는 수준이다. 물론 그러한 통신인프라를 구축하는 데 많은 비용이 들어가는 건 이해하지만, 정작 시장을 활성화시킬 노력을 하지 않았으니 말이다. (시장을 활성화시키기보단 소비자들이 알아서 기피하게 만들어버렸다.)
두번째로는 아이폰을 정말 잘 활용하기 위해선 가끔 아이폰을 멀리해야 할 때도 있다는 것. egoing님이나 김창준님이 이미 지적하고 계시는 것처럼, 가끔은 '온라인' 상태를 떠나 오프라인 세상에서 생각을 가다듬는 것이 필요하다. 특히나 나처럼 빠르게 변화하는 분야에 있는 경우--사실 요즘 안 그런 곳이 어디 있겠나 싶지만--더더욱 역으로 그런 시간이 필요하다. 안 그러면 내가 정보에 끌려가는지 내가 정보를 끌어가는지 알 수 없는 지경에 다다르게 된다. 뭐, 처음에야 이것저것 신기하니까 많이 만져보고 컴퓨터를 앞에 두고 아이폰을 들여다보고 있기도 하고 그랬지만 차츰 사용 빈도가 안정되어가는 느낌이다. 뭐든지 지나친 것은 아니한 만 못하다.
마지막으로 드는 생각은, 나도 아이폰 앱 개발 공부해야겠다는 것. 이거 생각보다 꽤 돈되는 시장이다. 아이폰 사용자의 1%한테만 유료앱 팔아도 1~3인 정도의 소규모 벤처 회사 운영할 만큼의 돈이 나올 수 있다. 주업은 아니더라도 잘만 하면 부수입으로 짭짤하게 벌 수도 있을 듯. 컴퓨터 윤리와 사회문제 수업 시간에 내가 아이폰을 쓰는 걸 보고 김진형 교수님이 잠깐 줘봐(-_-) 이러시더니 써보고 나서는 다음 학기부터 삼성 등의 지원을 받아 개설할 모바일 프로그래밍 과목에서 아이폰도 커리큘럼에 넣는 게 좋겠다고 하셨다.;;;
*
어쨌든 아이폰으로 인해 그동안 수도 없이 이야기되어왔던 국내 이동통신 시장의 왜곡된 구조가 깨지기 시작했다는 것은 큰 의미가 있다. 이미 어떤 앱을 만들어볼까- 하고 생각하면 이미 그런 앱이 등장하고 있을 정도이고, 아이폰으로 인해 소프트웨어 개발자 채용 공고가 증가했다는 보도도 나올 만큼 돌풍을 몰고 오고 있다. 게다가 그렇게도 요구했던 MacOS나 Linux 인터넷 뱅킹은 한두 개의 은행을 제외하고 지원할 기미조차 보이지 않더니 아이폰이 나오니까 갑자기 모바일뱅킹 표준화가 어쩌구 하면서 급물살을 타고 있다. 혹자의 걱정처럼 독과점을 외부세력의 또다른 독과점으로 깨는 것이기 때문에 경계할 필요도 있다고는 하지만, 아이폰 플랫폼이 당분간은 득세할 것이 분명해보인다. 오히려 우리나라의 휴대전화 제조사들과 통신사들에게 자극을 주어 보다 풍부한 모바일 소프트웨어 생태계가 만들어지는 데 촉매 역할을 했으면 좋겠다.
3년 전 E6600 듀얼코어 프로세서 기반의 데스크탑을 구입하면서 졸업할 때까지 쓰고 대학원 갈 때 한번쯤 더 업글해야겠다는 잠정적인 계획을 세우고 있었는데 오늘 드디어 그것이 실현되었다. 이번에 구입한 것은 i7 860 (2.8GHz) CPU와 해당하는 LGA1156 소켓 P55 칩셋 메인보드이고 무엇보다 가장 큰 지름은 256G SSD였다. 원래는 SSD를 60~80G 정도 짜리를 사서 운영체제와 프로그램만 올릴 생각이었는데, 학내 커뮤니티인 아라에 시가 80만원짜리 삼성 신제품 SSD를 50만원에 내놓은 매물이 있어 덥썩 물었다;;; (판매자 만나서 물어보니 경품으로 받았는데 쓸 일이 없단다-_-; SSD 받아서 확인해보니 실제로 사용시간 제로. +_+)
아름다운 쿼드코어 + 하이퍼쓰레딩 + SSD. 9800GTX+가 가장 낮은 점수가 나올 줄이야;
CPU와 SSD를 크게 지를 수 있었던 것은 그래픽카드와 하드디스크, 모니터, 키보드, 마우스 등을 예전 껄 그대로 쓰게 되었기 때문이다. 예전 데스크탑의 경우 메인보드에 내장그래픽이 없기 때문에 4만원 정도 하는 저가형 그래픽카드를 하나 사다 꽂아놓았고 잘 돌아가는 것까지 확인한 후 잠재워둔 상태. 이번 지름의 총합은 약 130만원 정도. 초등학교 때 펜티엄1 150MHz + RAM 32MB 짜리 삼성컴퓨터를 274만원 정도 주고 샀던 걸 기억하면 엄청난 발전이다.
내가 쓰는 프로그램 중 가장 고사양을 요구하는 슈프림커맨더를 돌려보았는데, 예전보다 확실히 부드럽게 돌아갔다. 하지만 CPU를 다 못 쓰고 4개의 코어 중 2개에서만 50~60% 정도를 왔다갔다하는 걸 볼 수 있었다. 슈프림커맨더가 멀티코어에 최적화되었다고는 하지만 i7의 모든 성능을 끌어낼 만큼 concurrency가 높지 않다는 것을 보여준다. (역시 parallel programming은 어렵다) i7 오버클럭에 GTX280을 붙여도 풀옵 풀해상도에서 40프레임을 넘지 않는다고 하니 슈프림커맨더를 지금의 스타크래프트 돌리듯 가지고 놀려면 하드웨어와 소프트웨어 모두 많이 발전해야 할 것 같다.
SSD의 성능이 특히 발군이었는데, 어지간한 프로그램은 아이콘을 누른 마우스 버튼에서 손을 미처 떼기도 전에 로딩이 끝나버리는 것 같은 느낌이었다. (MS Office, Visual Studio 등) 디스크에서 읽는 것보다 CPU를 더 많이 쓰는 프로그램들은 상대적으로 차이가 크지 않았는데, 이는 역시 컴퓨터 성능의 병목지점은 바로 디스크 I/O라는 것을 여실히 보여준다.
아무튼, 이런 쌔끈한 컴퓨터에 설치한 운영체제는 Windows 7. 아직 소매용으로는 공식 출시되지 않았지만 학교에서 곧 Enterprise 라이선스가 나올 것이기도 하고 이미 정품과 동일한 이미지 자체는 많이 돌아다니고 있기에 한 후배를 통해 부팅 가능한 USB를 만드는 방식으로 설치하였다. 윈도 자체 설치에 불과 20분도 안 걸렸다. (아직 인증하지 않은 상태로 사용 중)
Vista 64bit 버전을 2년 가까이 써왔던 사람으로서, Windows 7 64bit 버전은 정말 놀라우리만큼 많은 최적화가 이루어졌음을 바로 체감할 수 있었다. 컴퓨터 사양이 좋아진 것도 있지만 업글 직전 5일 정도 이미 세븐을 기존 데스크탑에서 돌려봤기 때문에 할 수 있는 말이다. 특히 3D 에어로 효과를 관장하는 Desktop Window Manager의 최적화가 많이 이루어져 UI 반응 속도도 빨라지고 DWM 자체가 소모하는 메모리나 CPU가 매우 줄어든 것을 관찰할 수 있었다. (심지어 게임을 실행할 때도 에어로가 꺼지지 않는다!)
속도나 성능 최적화 외에 기술적인 면에서 큰 변화는 없지만, 사람들은 Vista와 UI가 거의 똑같은 것 아니냐고 하는데 나는 Windows 7의 진정한 변화는 바로 UI에 있다는 생각이 든다. 그 중에서도 가장 맘에 드는 것은 '라이브러리'의 도입이다.
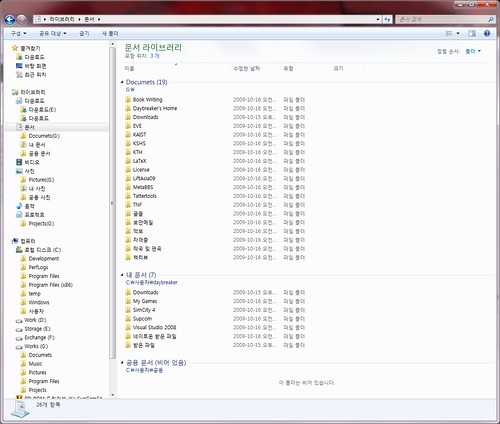
윈도7의 라이브러리 기능
Vista에서 '내 문서' 폴더를 임의의 다른 디스크에 두려고 하다가 꼬이는 바람에 탐색기의 사이드바 즐겨찾기에 '내 문서' 폴더가 2개나 생겨서 없애지도 못하고 불편했는데, 이번에는 개념 자체를 바꿔서 시스템이 사용자 디렉토리에 제공하는 기본 디렉토리들은 그대로 두고 '라이브러리'라는 개념을 도입해서 자기가 원하는 대로 다른 디렉토리를 해당 라이브러리에 추가하여 쓸 수 있게 하였다. 윈도 사용자 대부분이 운영체제/프로그램 설치용 파티션과 자신의 개인 데이터용 파티션을 구분해 사용하는 패턴을 드디어 UI에 제대로 반영했다고 볼 수 있다.
이 외에도 새로운 API를 추가함으로써 작업표시줄의 아이콘에 진행상황을 초록색 배경색이 점점 차오르는 식으로 표현할 수 있게 되었다든지 하는 세세하지만 user experience 측면에서는 상당히 중요한 개선 사항들이 있었다.
학교의 Windows 7 정식 라이선스가 제발 빨리 나오고 DreamSpark에도 제발 빨리 등록해주길 바라며, 세상은 그래도(?) 조금씩 발전하고 있구나-라는 느낌과 함께 글을 마친다.
작곡 수업 수강 기념으로 중학교 시절 작곡했던 곡들을 틈틈이 정리하고 있다. 그 중에서 가장 구성이나 화성이 잘 된 Morning Calm을 우선 작업하고 있다. (ly와 pdf를 포함한 실제 악보는 이곳을 참고한다. Creative Commons Share-Alike 조건으로 공개한다.)
특히 이번에는 Noteworthy Composer가 아닌, LilyPond라는 오픈소스 악보 조판 프로그램을 이용하여 아주 고품질의 악보를 만들고 있는데, 역시 물건이다. 이것이 무엇인가 하면, LaTeX을 써본 사람이라면 그나마 좀 쉽게 적응할 수 있는 종류의 프로그램으로, 텍스트 파일로 소스 코드를 작성하여 컴파일하면 그 결과물로 PDF 악보가 나온다. (MIDI 파일 출력도 가능하다) LaTeX과 달리 유니코드를 자체 지원해서 한글이나 한글 글꼴도 아무런 제약 없이 사용할 수 있다는 장점이 있다.

LilyPond로 컴파일(!)한 악보의 일부분
LilyPond를 왜 만들었나 하는 에세이를 보면 현대로 오면서 오히려 예전의 아름다운 악보 조판 기술이 기계적인 컴퓨터 소프트웨어로 대체되면서 잃은 악보의 감성적 typography를 다시 풀어내기 위한 많은 생각들을 엿볼 수 있다. 실제로 LilyPond를 써보면 상용 프로그램에 뒤지지 않는 정도가 아니라 더 아름다운 악보를 얻을 수 있음을 느낄 수 있다. 정말, 컴퓨터과학이 어떻게 다른 분야에 도움을 줄 수 있는지 잘 나타낼 뿐만 아니라, 그 자체로 인류 지식의 총량을 늘려주는 프로젝트라고 할 수 있다. (이런 훌륭한 프로그램이 오픈소스라는 건 인류의 축복이다!)
다만 역시 가장 큰 문제는 작곡가들이 아래와 같은 코딩을 하기는 쫌 힘들다는 것. 악보 note만 적는 거라면 뭐 어렵지 않을 수도 있겠지만 아래 스크린샷에서 나오지 않은, staff 관련 설정 등은 녹록치 않을지도 모르겠다.
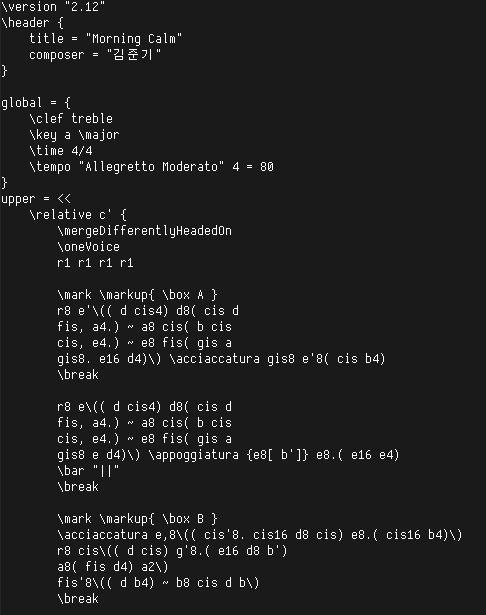
lilypond 소스 파일의 앞부분
사실, 작곡 수업 시간에 상용 프로그램인 Sibelius를 쓴다고 해서 왜 굳이 그걸 써야 하나 싶기도 하다. 물론 직접 들어보고 음원 파일로 만들어내는 건 아무래도 그런 상용 프로그램이 좀더 낫겠지만--아직 오픈소스나 무료소프트웨어 형태로 나온 고품질 음원 소스 및 연주·녹음 프로그램은 없는 듯--악보를 그리는 것은 이런 오픈소스를 사용할 만하지 않을까? 단 한 가지 내가 LilyPond에 원하는 것은 postscript로 컴파일하고 pdf로 생성하는 과정이 좀더 빨리 되었으면 좋겠다는 것. (에세이에서는 고품질의 악보를 얻기 위해 시간을 희생했다고 말하고 있긴 하지만...-_-) 대략 한번 악보를 뽑는데 10초 정도 걸리는데 이게 1~2초 정도로만 줄어도 참 편할 것 같다.